Designing Network design Spaces
I. Radosavovic R. P. Kosarahu R. Girshick K. He P. Dollar
Abstract
본 논문의 목표는 네트워크 설계에 대한 이해를 높히는 것이고 설정 전반에 걸쳐 일반화되는 설계 원칙을 발견하는 것이다. 개별적인 네트워크 인스턴스 설계에 초점을 맞추지 않고 네트워크 모집단을 매개 변수화하는 네트워크 설계 공간을 설계한다. 기존의 네트워크 디자인과 비슷하지만 디자인 space level이 더 높다. 본 논문은 네트워크 디자인의 구조적인 측면을 연구했으며, RegNet이라 불리는 단순하고 규칙적인 네트워크로 구성된 low-dimension 설계 공간에 도달했다고 한다. RegNet 매개변수화의 중심
insight는 놀랍게도 단순한데: 좋은 네트워크의 widths와 depths는 quantized linear function으로 설명될 수 있다. RegNet의 디자인 공간을 분석했는데, 최근 네트워크 디자인 실정과는 다름을 나타낸다. RegNet의 디자인 공간은 단순하고 flop 여역에서 매우 좋은 성능을 보이는 빠른 네트워크이다. RegNet은 EfficientNet 모델보다 GPU에서 5배나 더 빠르다.
1.Introduction
LeNet~ResNet까지는 효과적이면서 잘 알려지 네트워크 디자인이다. 위의 네트워크들은 convolution, network 그리고 데이터 크기, depth, residuals 등 각각이 중요하다는 것으 알려준다. 이것은 실질적인 네트워크 예시이며 디자인 원칙이다.
직접 네트워크를 설계하는 것이 큰 발전을 이뤄았지만, 선택의 수가 증가함에 따라 잘 최적화된 네트워크를 수동을 찾는 것은 어렵다. 따라서, NAS 라고 불리는 고정된 search space에서 가능한 좋은 네트워크를 찾아주는 기술이다.
NAS는 특정 설정에서 단일 네트워크 인스턴스만을 찾는 한계가 존재하며, 본 논문은 일반화를기반으로 하는 매우 단순한 네트워크를 찾는 것에 집중한다.
따라서, 본 논문은 수동의 디자인과 NAS의 이점을 조합한 새로운 네트워크 디자인 파라다임을 제시한다. 즉, 매개변수화 시킨 네트워크의 모집단인 디자인 공간들을 디자인한다. (여기서 디자인 공간은 탐색 공간이 아니다. 네트워크 인스턴스를 찾는 것이 아닌 말 그대로 공간을 디자인하는 것이다.)
전체적인 과정은 수동 디자인 방법과 유사한데, 모집단 수준으로 올리고 네트워크 디자인 공간들을 분산 평가를 통해 이끌어낸다.
먼저, VGG, ResNet, 그리고 ResNeXt와 같은 네트워크 구조를 찾았으며, 상대적으로 자유로운 디자인 공간을 가지는 AnyNet을 만들었고, 단순한 "regular" 네트워크로 이뤄진 저차원 디자인 공간을 발견했다. stage widths와 depths를 양자화 선형 함수로 결정할 수 있는 공간이다. AnyNet과 비교해 더 단순하고, 해석하기 쉽고, 좋은 모델들에 더 많이 집중할 수 있다.
RegNet의 디자인 공간은 적은 계산, 적은 epoch을 가진다. 더 쉽게 해석가능하고 우리가 생각한 방식과 이어진다. 또한, 기존의 일반적인 생각과 다르게, bottleneck 또는 inverted bottleneck을 사용하지 않고도 20 block 가까이 에서도 안정적임을 보인다.
RegNet은 모바일 환경에서 더 효과적이며, ResNe(X)t보다 더 좋은 성능을 보인다. 그리고 활성화 함수 횟수가 GPU와 같은 가속기의 런타임에 큰 영향을 미칠 수 있으므로 고정된 활성화함수에 대한 개선된 점을 강조한다. 또한, EfficientNet보다 5배나 더 빠르며, 일반화 성능도 높다.
네트워크 구조는 고려할 수 있는 디자인 공간 디자인의 가장 단순한 형태라고 할 수 있으며, 더 풍부한 설계 공간을 설계하는데 집중하면, 더 나은 네트워크로 이어질 수 있음을 나타낸다.
2. Related Work
Manual network design AlexNet부터 이어져온 manual network design은 많은 발전을 이뤄왔다. 이와 비슷하게 본 논문도 새로운 디자인 원칙을 발견했으며, manual design과 비슷하며 단지 디자인 공간 수준에서 실행되는 것이 차이점이다.
Automated network design 최근에는 NAS를 통해 효과적인 네트워크를 찾는데 집중한다. 본 논문은 search space를 디자인하는 방향으로 연구를 했으며, 2가지의 가정이 깔려있다. 1) 더 좋은 디자인 공간은 효과적으로 NAS의 search algorithm을 개선시킬 것. 2) 디자인 공간이 풍부해지면 더 좋은 모델을 찾을 수 있을 것.
Network scaling. 보통 네트워크를 만들 때는 특정 영역(flops, compare, etc)에서 최고의 성능을 내는 것으로 찾기 때문에, 다른 영역에서 사용하기에는 좋지않다. 따라서, 본 논문은, 일반적인 디자인 원칙을 발견함에 동시에 어떤 목표 영역에서도 최적화된 네트워크로 효과적으로 튜닝을 할 수있는 네트워크를 찾는다.
Comparing networks. 네트워크 디자인 공간들의 수는 거대하기 때문에, 뛰어난 comparison metric은 필수적이다. 최근에는 새플림 된 네트워크 모집단을 비교하고 분석하는 방법론이 존재하는데, 본 논문의 목표와 일치하며, 효과적인 방법을 제안한다.
Parameterization. 최종 양자화 선형 파라미터화는 이전 논문들과 비슷하지만, 다른 점이 2가지 있다. 1) 설계 선택을 정의하는 실증적 연구를 제공함. 2) 이전에 이해하지 못했던 구조 설계 선택에 대한 insight를 제공함.
3. Design Space Design
특정 설정에서 단일의 최고 모델을 찾거나 디자인하는 것보다는, 모델들의 모집단의 행동을 연구하는 것이다. 일반적인 디자인 원칙을 발견하고 이것을 모델의 모집단에 적용하는 것이다.
Radosavovic et al. [21][21]의 디자인 공간 개념을 사용하는데, 디자인 공간으로부터 모델들의 샘플링하고, 모델 분포를 생성하며, 그리고 고전 통계방법으로 이러한 디자인 공간을 분석할 수 있다는 것이다.
본 논문은 자유로운 디자인 스페이스에서 계속해서 단순한 버전의 initial network을 디자인하는 design space design을 제안한다. 입력은 초기의 디자인 공간이며 출력은 더 단순하거나 좋은 성능을 가진 모델들의 모집단을 가지는 디자인 원칙인 재정의된 디자인 공간이다.
본 논문에서 제안하는 RegNet의 디자인 공간은 다음과 같다. 1) 허용하는한 네트워크 구성의 차원과 유형 측면에서 단순화 2) 최고 성능 모델들의 더 높은 집중이 포함되어있으며, 3) 분석 및 해석이 더 용이해야한다.
3.1 Tools for Design Space Design
본 논문은 디자인 공간을 평가하기 위해 [21][21]의 방법을 사용하는데, 해당 설계 공간에서 모델 세트를 샘플링하고 모델 오류 분포 결과를 특성화하여 설계 공간의 품질을 정량화한다. 이것은 분포를 비교하는 것이 더 강인하며 search algorithms을 사용하는 것보다 더 유익하다.
모델의 분산을 얻기위해 디자인 공간에서 n개의 모델을 샘플링하고 학습한다. 효율성을 위해 400M FLOPs와 10 epochs만을 사용한다. n이 100일 때, 모델들 모두를 학습하는 것과 ResNet-50을 학습하는 것과 같은 FLOPs를 가진다. (ImageNet에서 학습한 결과)
[21][21]의 디자인 공간의 퀄리티를 분석하기위 empirical distribution function (EDF)를 사용한다.
$e_i$는 모델의 에러이며 $e$는 threshold이다.
밑의 그림 2의 좌측은 $n=500$에서 AnyNetX 디자인 공간으로부터 샘플링한 모델들의 EDF 이다. 훈련된 모델의 모집단이 주어지면 다양한 네트워크 속성과 네트워크 오류를 시각화하고 분석할 수 있다.

여기서, empirical bootstrap를 통해 최고 모델이 속하는 범위를 추정할 수 있다.
즉, 이렇게 요약할 수 있다. 1) 디자인 공간으로부터 n개의 모델을 샘플링하고 학습하여 모델의 분포를 얻는다. 2) EDF를 사용해 디자인 공간의 퀄리티를 계산하고 시각화한다. 3) 디자인 공간의 속성을 보고 empirical bootstrap을 통해 insight를 얻는다. 4) 이것으로 다시 디자인 공간을 재정의하여 더 나은 디자인 공간을 만든다.
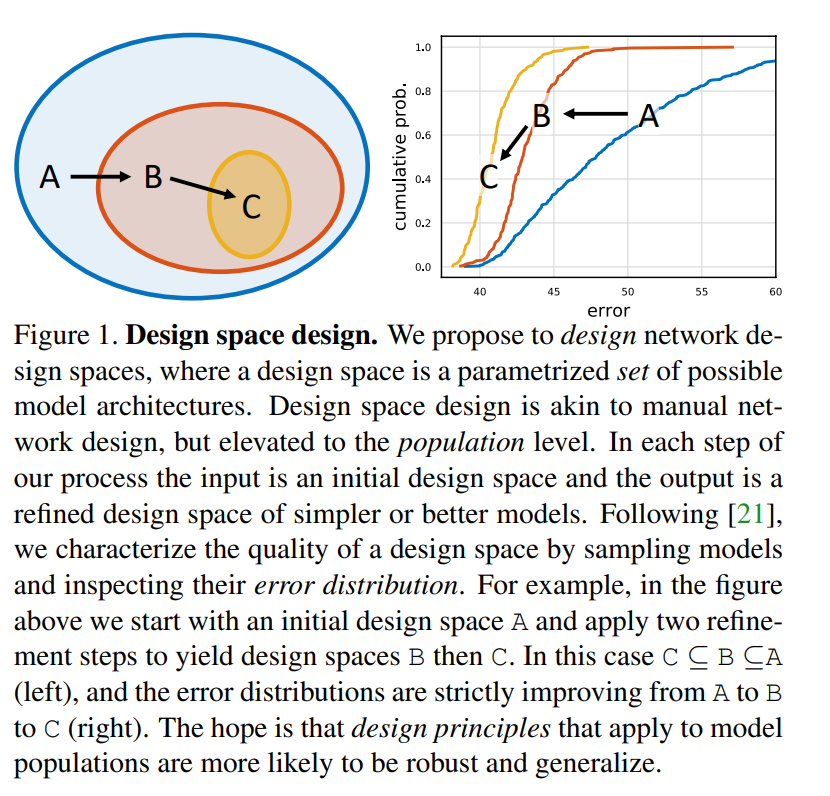
3.2 The AnyNet Design Space
이 section에서는 표준이며 고정된 네트워크르 블럭을 가정한 네트워크의 구조를 탐구하는 것이다. 즉, 블럭의 수, 블럭의 너비 그리고 블럭의 다른 매개변수들에 대한 탐구다. 이러한 것들은 계산량, 매개변수 그리고 메모리의 분포를 결정하는 동시에 정확도와 효율성을 결정한다.
AnyNet의 디자인 공간은 간단하면서 쉬운데, 그림 3의 a와 같이 입력단의 stem, 그 뒤에 body 그리고 class를 예측하는 head 부분으로 나눠져있다. 여기서 stem과 head를 최대한 고정시키고 네트워크의 body를 변경하여 계산량과 정확도를 결정한다.

body는 총 4개의 stages로 구성되어 있으며, 계속해서 resolution을 줄여간다. (그림 3의 b) 각 stage는 개별적인 block들을 가지며, 각각의 stage는 block의 갯수 ($d_i$), block의 너비 ($w_i$), 그리고 block 매개변수를 가진다. 이러한 AnyNet의 구조는 매우 방대하다.
그림 4에서 볼 수 있듯이 대부분의 실험에서는 residual bottleneck blcok을 사용하며, 이것을 x block 이라고 지칭한다. 그리고 이러한 block으로 이뤄진 네트워크를 AnyNetX라고 하며, 네트워크 구조가 최적화 되었을 때, 놀랍운 효율성을 보인다.
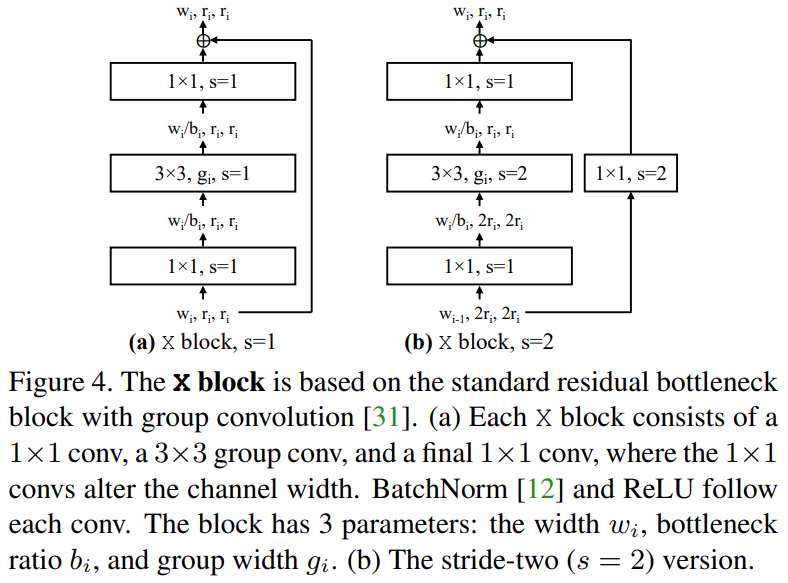
AnyNetX의 디자인 공간은 총 16단계로 정해지는데 4개의 stage와 각 stage에서 4개의 매개변수를 가진다. blocks의 수 ($d_i$), block의 너비 ($w_i$), bottleneck ratio ($b_i$), 그리고 group width ($g_i$)이다. $d_i \leq16$인 log-uniform sampling, $w_i \leq 1024$인 8의 배수, $b_i \in {1,2,4}$, $g_i \in {1,2,...,32}$ 이다. $n=500$, epoch 은 10, 그리고 목표 계산량은 300MF~400MF이다.
총 $10^18$의 가능성이 나오며 이것이 AnyNetX의 디자인 공간이다. ~$10^18$의 최고성능 모델을 찾는 것이 아닌 일반적인 디자인 원칙을 찾는데 집중했으며 디자인 공간을 이해하고 재정의 하는데 도움이 된다. 그리고 4가지의 접근법을 사용해 AnyNetX를 총5가지로 나눴다.
AnyNey$X_A$ 초기의 AnyNetX의 디자인 공간이다.
AnyNet$X_B$ 여기서 제한하는 부분은 bottleneck ratio를 공유하는 것이다. 즉, 모든 stage에서 bottleneck ratio $b_i = b$로 고정한다. 똑같이 500개의 모델을 만들어 AnyNet$X_A$와 비교했으며, 그림 5의 좌측은 결과이다. 이것으로 보아 bottlenck ratio는 그렇게 큰 차이를 못내는 것 같으며 그림 5의 우측은 b에 따른 결과를 보여준다.
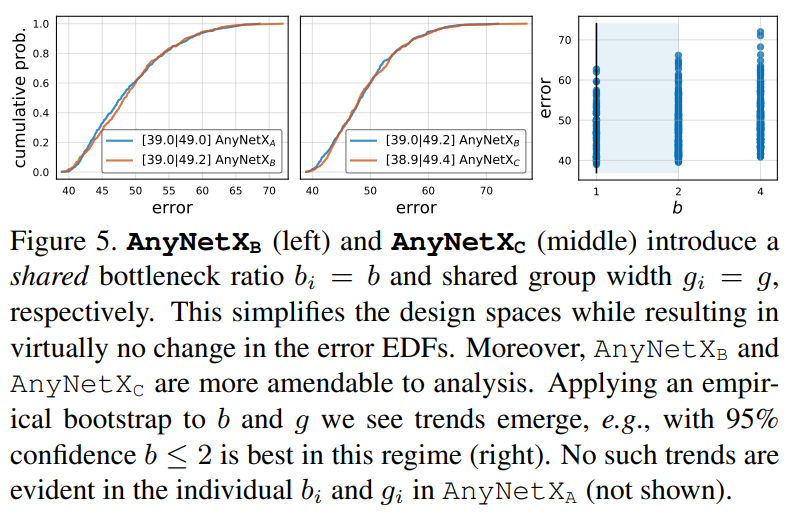
AnyNet$X_C$ 여기서는 AnyNet$X_B$에서 group convolution을 공유했다. 성능 변화는 거의 없어 보이며 그림 5의 중앙을 보면 알 수 있다.

AnyNet$X_D$ 여기서는 AnyNet$X_C$의 좋은 네트워크와 안좋은 네트워크를 탐구했으며, 그림 6에서 볼 수 있다. 결과적으로 widths가 증가할 수록 성능도 증가하는 패턴을 발견했다. 따라서, $w_{i+1} \geq w_i$라는 디자인 원칙을 발견했다. 그림 7에서 확연하게 알 수 있다.

AnyNet$X_E$ 여기서는 stage depths $d_i$를 width와 같이 형성했다. 즉, $d_{i+1} \geq d_i$이다. 그림 7에서 볼 수 있으며, $w_i$와 $d_i$는 각각 4!만큼 줄어들었다. 따라서, $O(10^7)$만큼 가진다. <-> $O(10^18)$
3.3 The RegNet Design Space
그림 8의 상단좌측은 AnyNet$X_E$의 최고 20개의 모델을 보여준다. 또한, grady curves는 각각 모델의 편차를 보여주는데, 패턴이 나타난다. ($w_j=48\cdot(j+1)\ and\ 0 \leq j \leq 20$)이다. 놀랍게도 이 사소한 linear fit은 상위 모델에 대한 네트워크 너비 증가의 모집단 추세를 설명하는 것 같다. 하지만, linear fit는 각 블럭마다 다른 width를 할당하는 것처럼 보일 수 있다.

이러한 패턴을 개별적인 모델들에 적용하기위 piecewise constant function을 양자화하는 전략을 선택했다. 즉, 각 block의 너비들을 linear parameterization로 할당한다
$d$: depth, $w_0 >0$: initial width, $w_\alpha >0$: slop, 그리고 각 block $j<d$에서 다른 너비인 $u_j$를 가진다.
$u_j$를 양자화 하기위해서 추가적인 매개변수인 $w_m >0$을 소개한다. 먼저, $u_j$로부터 각 블럭 j 에서 $s_j$를 계산한다.
그 후에, $u_j$를 양자화 하기위해 $s_j$를 반올림하고 블럭당 너비인 $w_j$를 양자화하여 계산한다.
block당 width인 $w_j$를 stage당 width로 확장하고 $w_i=w_0\cdot w_m^i$와 같이 된다. 그리고 블럭의 갯수인 $d_i=\sum_j1[\left [s_j \right] = i].$가 된다. 4단계 네트워크 만 고려할 때 다른 수의 stage를 발생시키는 매개 변수 조합을 무시한다.
AnyNetX에 위의 매개변수화를 적용해서 테스트를 진행했으며, d로 네트워크 깊이를 설정하고 grid search를 통해 $w_0,\ w_\alpha$를 찾았다. 그 후 $w_m$은 관측된 블록당 너비로 예측된 $e_{fit}$라고 불리는 평균 로그 비율을 최소화한다. 그림 8의 상단 우측에서 dashed curves는 양자화 linear fits가 최고 모델 (solid curves)와 유사하다.
fitting error인 $e_{fit}$와 네트워크 에러를 살펴보기위해 그림 8의 하단을 보면 된다. 각 디자인 공간에서 최고 모델이 좋은 linear fits를 가짐에 주목했으며, 실제로 각각의 디자인 공간 안에서 최고 모델은 $e_{fit}$의 좁은 영역 안에 포함된다. 그리고 평균에도 주목했는데, $X_c$에서 $X_E$까지 감에 따라 $e_{fit}$가 개선되며 이것은 $w_i$와 $d_i$가 증가하면 성능도 좋아짐을 나타낸다.
더욱더 디자인 공간을 제한했으며, 6개의 파라미터들인 $d,\ w_0,\ w_m, w_\alpha,\ b,\ g$로 구성된다. 각각으로 위의 2~4 수식을 통해 block width와 block depth가 정해지고 이것은 RegNet이라고 부른다. $d<64,\ w_0,w_\alpha <256,\ 1.5 \leq w_m \leq 3$ and $b$ and $g$는 전의 AnyNet$X_E$와 같다.
그림 9의 좌측을 보면 AnyNetX보다 RegNetX가 훨씬 더 좋은 성능을 보인다. 또한 2가지의 단순화를 시켰는데, 그림 9의 중앙을 보면 1) $W_m=2$(stage마다 width는 2배)로 성능을 증가시킴 2) $w_0=w_\alpha$는 수식 2인 선형 매개변수화를 단순하게 만들며 성능 또한 좋아진다. 하지만, 다양성을 위해 이와같은 방법은 사용x 그리고 그림 9의 우측은 RegNetX의 random search 효율성을 보여준다.

표1은 AnyNetX와 RegNetX의 디자인 공간 크기에 대한 표이며, 약 $10^10$만큼 줄었지만 여전히 RegNet은 다양성을 가지고 있다고 주장한다.

3.4 Design Space Generalization
본논문에서 RegNet을 디자인 했지만, 더 일반화된 설정을 발견했다.

일반화를 위해서 먼저 AnyNet을 더 많은 flops, 더 많은 epochs 그리고 5-stage networks로 구성해서 성능을 테스트 했다. 여기서도 RegNet이 성능이 더 뛰어 났으며, overfitting의 징조를 보지 못했다. 이것은 아직도 RegNet이 더 많은 stages 에서도 일반화될 수도 있다는 것이다.
4. Analyzing the RegNetX Design space
RegNetX의 디자인 공간을 분석하고 공통적으로 deep network 디자인에서 많이 선택하는 것을 조사했다. 여기서는 $N=100,\ epoch=25,\ learning\ rate=0.1$로 사용했다.
RegNet trends.

1) depth: 약 20 blocks(60 layers)에서 최적화된다. -> 깊이가 늘어날 수록 성능 증가한다는 일반적인 이론과 다름 2) bottleneck ratio: 1.0에서 최적화된다. -> bottleneck 구조가 좋다는 일반적인 이론과 다름 3) width multiplier: 2.5에서 최적화된다. -> 일반적인 이론은 2배를 보통 한다. 4) 남은 매개변수들: 복잡해질수록 성능이 증가한다.
Complexity analysis.
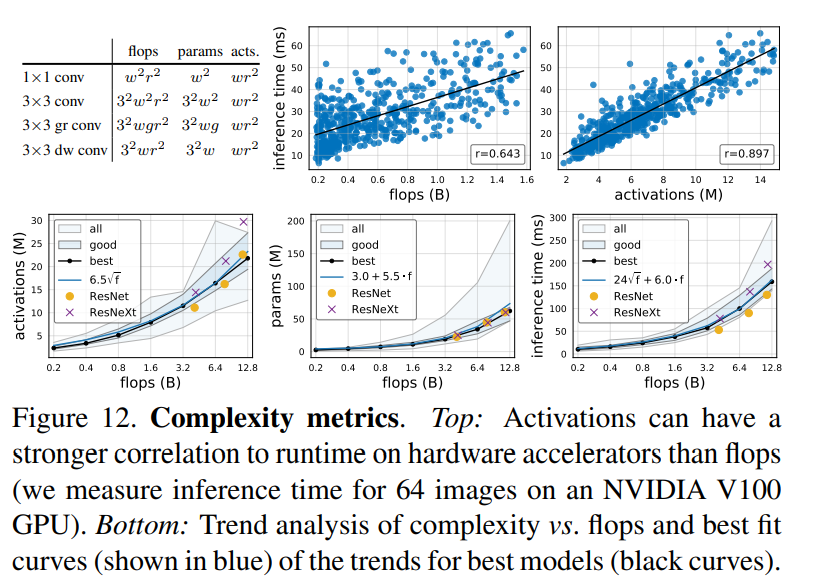
모든 conv layers의 출력 텐서 크기를 뜻하는 activations에 대한 탐구이다. 그림 12의 상단을보면 actiavtions은 GPUs, TPUs와 같은 메모리가 제한된 하드웨어 가속이의 실행시간에 크게 영향을 준다. 그림 12의 하단에서 특히 모집단의 최고 모델을 보면, activaations는 FLOPs의 제곱근을 증가시키며, 매개변수들도 선형적으로 증가시키며, 실행시간은 선형과 제곱근의 조합으로 설명될 수 있다.
RegNetX constrained 위의 결과들을 종합해 새로운 디자인 공간을 정의했다. 1) 그림 11의 상단을 참고하여 $b=1,\ d \leq 40,\ and\ w_m >2$로 설정함. 2) 그림 12 하단을 참고해 매개변수와 activation을 제한함. 3) 따라서, 빠르고, 적은 매개변수와 적은 메모리를 가지는 모델을 만들었으며, 그림 13에서 확인할 수 있다.

보는 것과 같이 모든 FLOPs에서 더 좋은 성능을 보인다.
Alternate design choices.

최근 모바일 네트워크에서 inverted bottleneck (b<1)와 depthwise conv(g=1)을 강조했는데, 이와 같은 방법은 그림 14 좌측을 보면 성능 저하를 가져오는 것을 확인할 수 있다. 그리고 input image를 증가시키면 도움이 된다고는 하지만, regNetx는 $224\times224$로 고정하는 것이 제일 좋은 성능을 보인다.
SE. 자중 사용되는 Squeeze-and-Excitation (SE) op를 추가해 RegNetY로 부르며 그림 14의 우측과 같이 좋은 성능을 보인다.
5. Comparison to Existing Networks.
ImageNet에서 비교를 위해 RegNet 매개 변수의 25가지로 임의 설정에서 최상의 모델을 선택하고 상위 모델에 대해 100epoch으로 5번 재훈련한다.
그림 15와 그림 16은 각각 RegNetX와 RegNetY의 성능을 보여준다. 여기서 흥미로운 패턴을 발견했는데, 상위 플롭 모델은 3 stage에 많은 수의 블럭이 있고 마지막 단계에 적은 수의 블럭을 가지는데 이것은 ResNet과 유사하다.
본 논문의 목표는 공평한 비교와 쉽고 재생산할 수 있는 baselines를 제공하는 것이다. 따라서, 특별한 학습 구성이나 정규화를 사용하지 않았다.

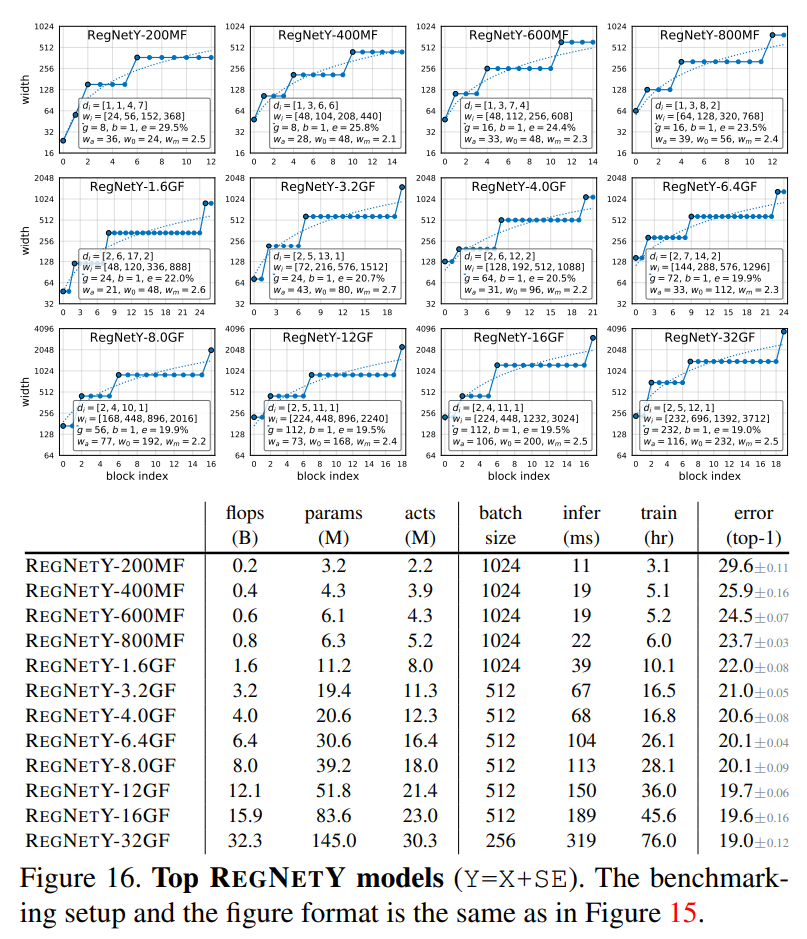
5.1 SOTA Comparision: Mobile Regime
모바일 영역은 보통 600MF보다 작은 영역을 뜻하는데 표2에서 보는 것과 같이 RegNet이 더 좋은 성능을 보인다.

또한, 비교된 네트워크 구조는 더 긴 학습 시간과 많은 정규화를 사용했기 때문에, RegNet이 더 좋은 성능을 가져올 수 있다고 생각한다.
5.2 Standard Baselines comparison: ResNe(X)t
ResNet과 ResNeXt에 대한 비교이며, 모든 학습 설정은 ResNet과 ResNeXt를 따랐다. 그림 17과 표 3을 보는 것처럼 매우 좋은 성능을 보인다.


activations으로 따로 구별한 이유는 activations의 수가 GPU와 같은 가속기의 실행시간에 영향을 주기 때문이다. 따라서, RegNetX는 적은 실행시간을 가지므로 효과적이다.
5.3 SOTA Comparison: Full Regime
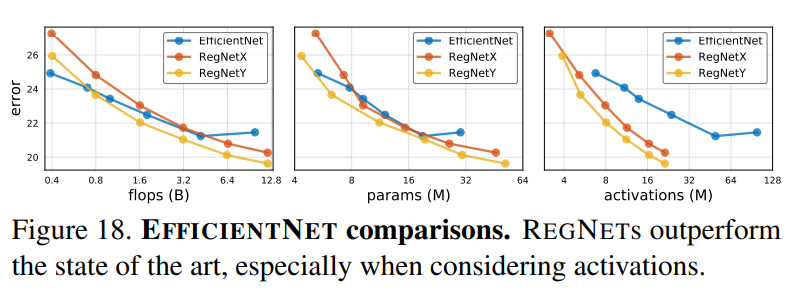
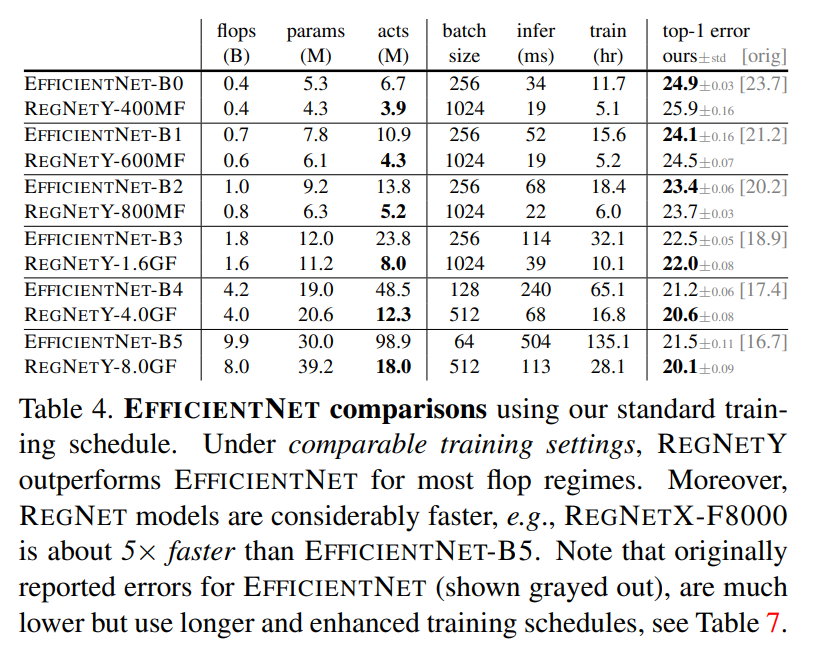
EfficientNet과의 비교이다. EfficientNet을 재구현하였으며, 본 논문 저자들이 정한 학습 설정인 100 epoch과 정규화 비사용을 사용함. 오직 learning rate와 weight decay를 사용했으며, RegNet과 같은 설정이다. 결과는 그림 18과 표 4에서 볼 수 있으며, 적은 flops에서는 EfficientNet이 더 좋지만 큰 flops에서는 RegNetY이 더 좋은 성능을 가진다. 또한, EfficientNet이 더 많은 activations을 가지는 것으로 보이는데, 이것은 추론 시간을 증가시켜 RegNetX-8000이 EfficientNet-B5보다 약 5배 빠르다.
6. Conclusion
새로운 네트워크 디자인 표준을 제시했으며, 네트워크 디자인 공간을 디자인 하는 것이 유망있는 기술이면 좋겠다.