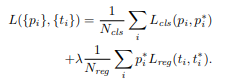VarGFaceNet: An Efficient Variable Group convolutional Neural Network for Lightweight Face Recognition
M. Yan M. Zhao Z. Xu Q. Zhang G. Wang Z. Su
Abstract
본 저자들은 VarGFaceNet이라고 불리는 효율적인 variable group CNN을 제안한다. parameter와 cost를 줄이는데 집중을 했다. 특히, 특정한 설정이 필요한데, 네트워크의 입력단인 head와 fully-connected layer에서 특정 embedding stting이 필요하다. 저자들은 재귀적인 knowledge distillation을 사용했으며, teacher와 student 사이의 차이를 없애는 방향으로 접근하였다. 2019년 LFR deepglintlight에서 1등을 했다고 한다. github: https://github.com/zma-c137/VarGFaceNet
1. Introduction
얼굴 인식 분야에서 계산량을 줄이는 많은 논문들이 있지만, 여전히 제한적이다. SqueezeNet, MobileNet, ShuffleNet과 같이 $1\times1$ convolution을 사용해 사용량을 줄인 것들이 있다. MobileNet v1의 경우 depthwise separable convolution을 사용했으며, 그에 기초해 MobileNet v2는 반전된 bottlenect 구조로 네트워크의 분별능력을 강화했다. ShuffleNet 종류는 pointwise group convolution과 channel shuffle operation을 통해 계산량을 줄였다. VarGNet은 variable group convolution을 통해 블럭당 불균등한 계산량을 해결했다. 특히, 같은 kernel 크기에서 depthwise convolution보다 더 많이 수용할 수 있다. 그러나 VarGNet은 얼굴인식에는 적합하지않는데, 네트워크 시작단에서 공간영역을 반으로 줄이는 특성 때문이다. 얼굴 인식은 얼굴 이미지의 자세한 정보가 중요하다. 또한, average pooling layer가 마지막 conv와 fc layer 사이에만 있어, 충분한 분별 정보를 추출할 수 없다.
VarGNet을 기반으로 제안하는 VarGFaceNet이다. VarGNet과는 다르게 추가한 부분들이 있다. 1) SE block과 PReLU를 추가함 2) 더 많은 정보를 보존하기위해 네트워크 시작 부분의 downsample process 제거 3) embedding 때, fclayer 전에 $1 \times 1 \times 512$에 variable group convolution 적용.
네트워크의 해석 능력을 강화시키기위해 학습하는 동안 Knowledge distillation을 적용했다. 더 작고 효율적인 네트워크를 위해 pruning, quantization 등이 있는데, knowledge distillation의 경우 모델 변경이 자유로워 선택했다. Hinton 11은 knowldege distillation 개념에 대해서 소개했으며, FitNet은 feature distillation 아이디어를 채택하여 student network가 teacher network의 hidden feature를 따라할 수 있도록 했다. 그 후로, transferring the fature activation map 10과 activation-based and gradient-based Attention Maps 25 이 시도되었다.최근에는 ShrinkTeaNet 6은 angular distillation loss로 teacher model의 angular information에 집중했다. 게다가, teacher model과 student model 사이의 차이에 의해 발생하는 optimization의 복잡성을 해결하기위해 다음 세대를 위해 pretrained model을 한 세대에 student를 학습하는데 사용하였다.
본 논문은 LFR challenge에서 1등을 달성했으며, 좋은 성능을 보였다.
Contribution
- VarGNet에서 다른 head setting과 새로운 embedding block을 제안했다. 새로운 embedding block은 처음에 $1 \times 1$ convolution을 통해 1024 channel로 확장하고 variable group conv와 pointwise conv를 적용했다.
- generalization을 위해 recursive knowledge distillation을 사용함
- variable group convolution의 효율성과 angular distillation loss와의 동일성을 분석함.
2. Approach
2.1 Variable Group convolution
Group convolution은 AlexNet부터 이어져온 기술이다. ResNext에서는 group convolution의 개수에 대해서 설명했으며, MobileNet들은 이것으로 depthwise separable convolution을 만들었다. 하지만, 계산량 대부분 (95%)을 $1\times1$에서 사용된다. 따라서, 이런 차이는 embedding 방법에는 적합하지 않는다. 따라서, VarGNet은 channel를 상수 $n_i$로 나눈 $S$를 사용한다. VarGNet의 계산량은 다음과 같다.
입력층의 $h_i \times w_i \times c_i$이며 출력층의 $h_i \times w_i \times c_{i+1}$ 이다. $k$는 kernel의 크기이다. 만약, MobileNet의 depthwise separable convolution 대신에 group convolution이 쓰인다면 pointwise convolution 같이 나온다.
variable group convolution과 pointwise convolution 사이의 계산량 비율은 $\frac{k^2S}{c_{i+2}}$이며 depthwise convolution과 pointwise convolution 사이의 비율은 $\frac{k^2}{c_{i+2}}$ 이다. 실제로 $c_{i+2}\gg k^2,\ S>1,$이므로 따라서, $\frac{k^2S}{c_{i+2}} > \frac{k^2}{c_{i+2}}$ 이다. 따라서, depthwise separable convolution 대신 pointwise convolution의 하단에 variable group convolution을 사용하면 블록 내에서 더 계산적으로 균형을 이룬다. 게다가, $S>1$은 더 많은 MAdds와 더 큰 네트워크 수용력을 나타내며, 더 많은 정보를 추출할 수 있음을 나타낸다.

2.2 Blocks of Variable Group Network
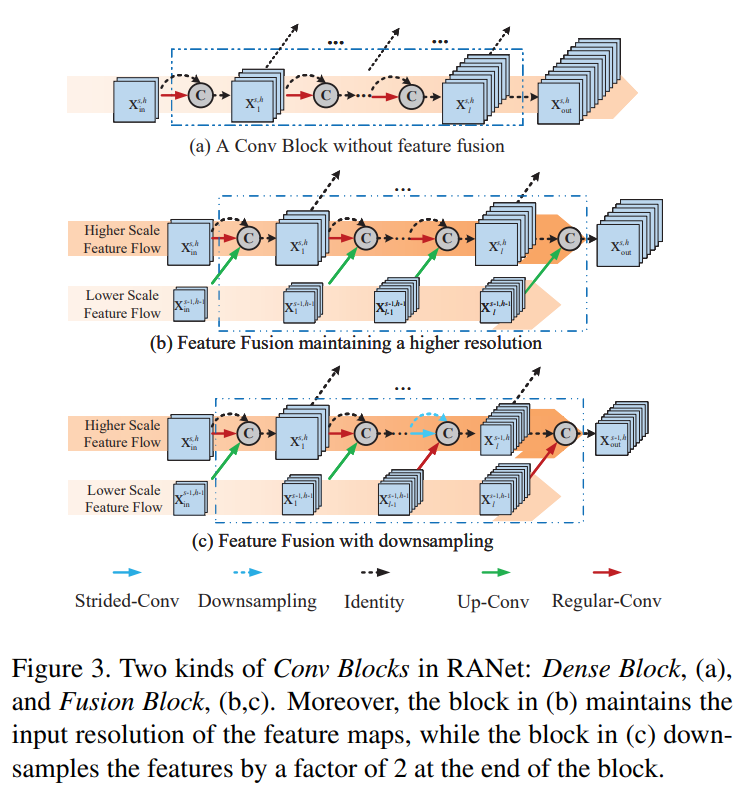
VarGNet은 normal block에서 입력 채널과 출력 채널의 수를 같게 했지만, 시작부분 block에서는 일반화 능력을 유지하기위해 C 채널 수를 2C 채널 수로 확장했다. 위의 그림 (a)과 (b)와 같이 구조를 쌓았으며, 구별능력 향상을 위해 normal block에 SE block을 추가하고 ReLU 대신 PReLU를 사용했다.
2.3 Lightweight Network for Face Recognition
2.3.1 Head setting
face recognition은 규모가 큰 문제이다. lightweight network를 유지하기 위해 $3\times3$ Conv에 stride를 1로 설정해 사용했으며 (VarGNet에 비해), 시작부분에서 downsampling이 아닌 그대로 사용했다. 그림 1의 (c)에서 확인할 수 있다.
2.3.2 Embedding setting
얼굴의 embedding을 얻기 위해서 많은 논문들이 마지막 convolution 뒤에 fc layer을 붙이는데 상대적으로 매우 큰 계산량을 차지한다. 예를들어 ReNet 100의 경우 49M에서 12.25M을 차지한다.
본 논문에서는 variable group convolution을 통해 fc layer 전에 $1\times1\times512$ feature map으로 줄어들게하였으며, fc layer에서 단지 1M만 사용한다. (그림 1의 (d)에서 확인 가능) 하지만, 이렇게 하면 feature tensor가 제한될 수 있어 마지막 conv layer 전에 늘리고 줄이는 방식을 통해 필수적인 정보는 감소되는 것을 방지하도록 했다.
1) $1\times1$ convolution을 통해 $7\times7\times320$에서 $7\times7\times1024$로 확장.
2) $7\times7$ variable group convolution을 통해 $1\times1\times7$로 줄어들게 함.
3) pointwise convolution을 통해 $1\times1\times512$로 만든다.
이렇게 새로운 embedding은 기존의 embedding인 30M에 비해 5.78M의 계산량을 가진다.
2.3.3 Overall architecture

약 20M 메모리와 1G의 FLOPs를 사용한다. 전체적인 구조는 표 1에서 확인할 수 있다.
2.4. Angular Distillation Loss
Knowledge distillation은 큰 네트워크에서 작은 네트워크로 해석 능력을 전달할 수 있다. scores/logits 또는 embeddings/feature magnitude에 L2/cross entropy를 사용한다. 하지만, 이런 것은 제한된 정보를 주거나 over-regularized 될 수 있다. 따라서, angular distillation loss라는 것을 사용해 유용한 정보를 추출하고 over-regularization을 피할 수 있다. 밑의 식은 angular knowledge distillation 이다. $F_t^i$는 i번째 teatcher, $F_s^i$는 i번째 student이다.
본 논문에서는 위의 angular knowledge distillation을 구현의 편의성을 위해 변형하여 다음과 같이 사용한다.
또한 arcface를 차용하여 angular information에 더 지 ㅂ중한다.
따라서, 최종 학습시킬 objective function은 다음과 같다.
본 논문에서는 실험적으로 $\alpha=7$을 사용한다.
2.5 Recursive Knowledge Distillation
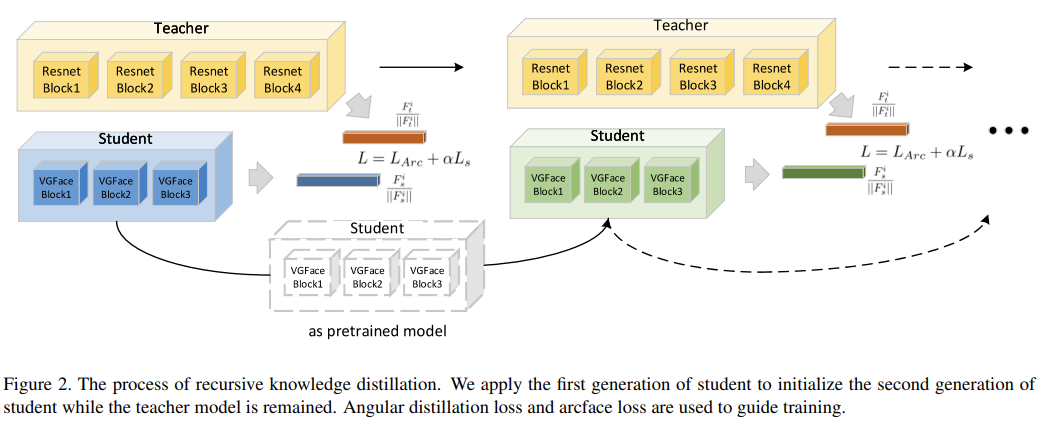
단 한 세대의 Knowledge distillation은 큰 모델과 작은 모델 사이의 간극을 때때로 매꿀 수 없을 때도 있다. 따라서, student network의 구별 능력과 일반화 능력을 향상시키기 위해 recursive knowledge distllation을 사용한다. 그리고, teacher network를 매 새대 같은 것을 사용해 지도되는 내용이 불변하도록 한다. Recursive knowldege distillation을 통해 얻는 이점은 다음과 같다.
- teacher로 부터 곧바로 지도를 받아 좋은 초기화를 제공할 수 있다.
- classification loss와 angular information 사이의 충돌을 다음 세대를 통해 해결할 수 있다.
3. Experiments
1) y2 network (deeper mobilefacenet)과 비교 2) 다른 teacher model들과 비교 3) LFR2019 Challenge에 적용한 성능
3.1 Datasets and Evaluation Metric
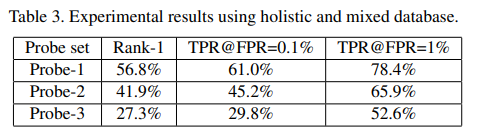
먼저 Training에는 LFR2019에서 제공하는 MSIM으로 모든 학습을 진행했으며, 모든 어굴 이미지는 RetinaFace로 $112\times112$로 재조정해서 사용했다. Testing에서는 Trillionpairs dataset을 사용했다. 위의 데이터 셋은 ELFW, DELFW를 포함하는 데이터셋이다. 모든 테스트 얼굴 이미지는 preprocess와 resize를 했다. 마지막으로 Evaluation은 LFW, CFP-FP 그리고 AgeDB-30을 사용했다. 또한, TPR@FPR=1e-8로 evaluation metric을 사용했다.
3.2 VarGFaceNt rain from scratch

Validation set에서 mobilefacenet (y2)와 비교한다. 표 2에서 확인할 수 있으며, 전체적으로 본 저자들이 만든 네트워크의 성능이 더 높게 나온다. 직관적으로 2가지의 나은 성능을 볼 수 있다.
- y2에 비해 더 많은 파라미터들을 포함하고 있으며, 마지막 conv layer에서 256에 비해 320 채널 수를 가진다.
- y2의 경우 256에서 512로 확장하지만, 본 논문의 네트워크는 320에서 1024로 확장한다. 따라서 더 많은 정보를 가진다.
3.3 VarGFaceNet guided by ResNet
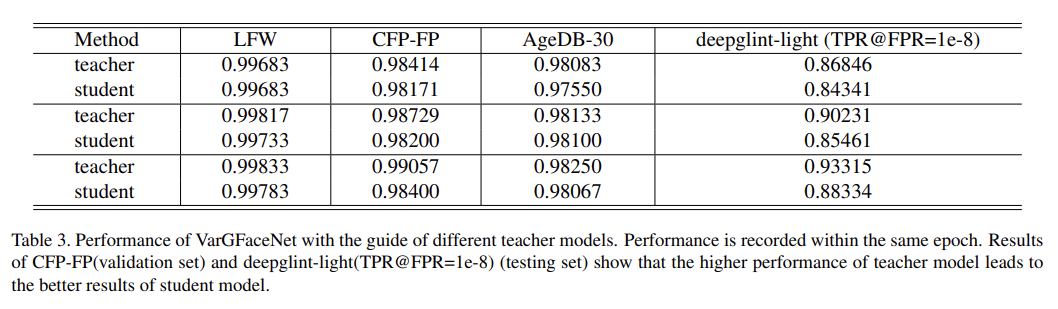
angular distillation loss를 사용해 knowledge distillation을 했다. teacher model로는 SE block이 포함된 ResNet 100을 사용했다. 결과는 표 3에서 확인할 수 있다. 표의 결과에 따라 VarGFaceNet이 더 작은 네트워크 이지만, teacher model을 따라잡을 수 있음을 알 수 있다.
VarGFaceNet과 VarGNet을 비교했다. 여기서 VarGNet은 VarGFaceNet과 같은 head 설정을 했으며, 결과적으로 VarGFaceNet이 더 좋은 성능을 보인다. 즉, VarGFaceNet의 embedding setting이 더 적합하는 것을 알 수 있다.

3.4 Recursive Knowledge Distillation
VarGFaceNet을 recursive Knowledge Distillation으로 validation set에 사용한 결과이다. 표 5에서 확인할 수 있으며, LFW와 CFPFP는 0.1%의 상승을, deepglintlight는 0.4%의 상승을 확인할 수 있다. 저자들은 더 많은 generation을 통하면 성능을 더 증가할 것으로 생각한다.

4. Conclusion
본 VarGFaceNet으로 효율성과 성능 사이의 trade-off를 더 좋게 할 수 있음을 알게되었다. head setting과 embedding setting으로 information을 보전할 수 있으며, angular distillation loss와 recursive knowledge distillation을 통해 해석능령이 상승한 가벼운 네트워크를 만들 수 있었다.
'공부 > 논문 리뷰' 카테고리의 다른 글
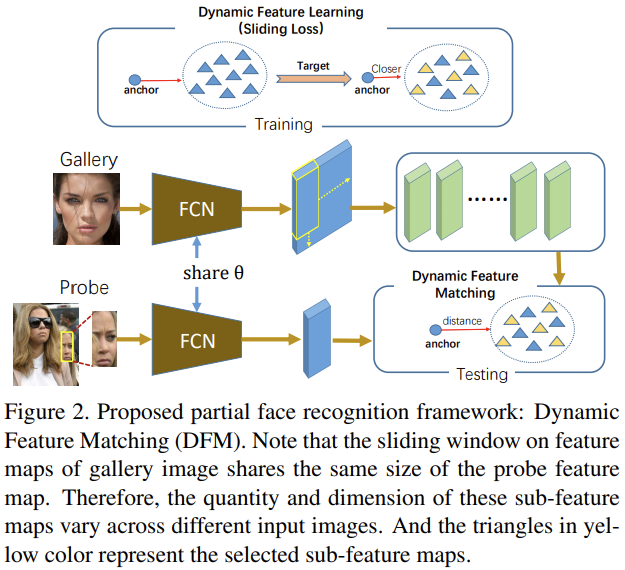
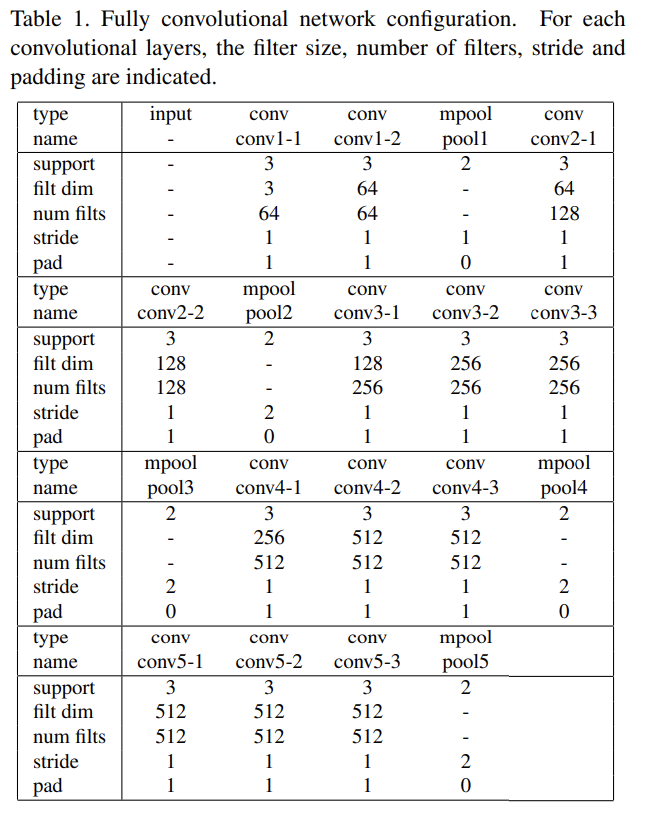
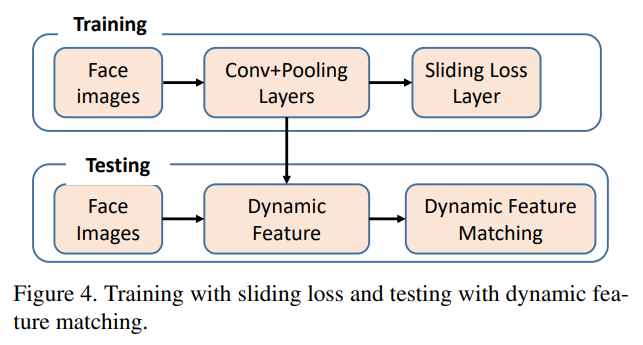
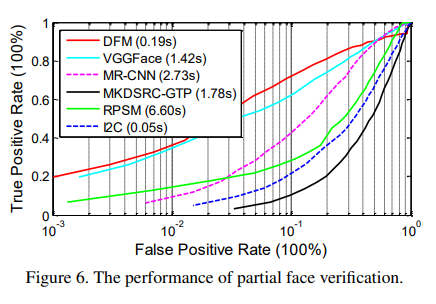
| [논문 리뷰] Dynamic Feature Learning for Partial Face Recognition (0) | 2021.02.02 |
|---|---|
| [논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.01.13 |
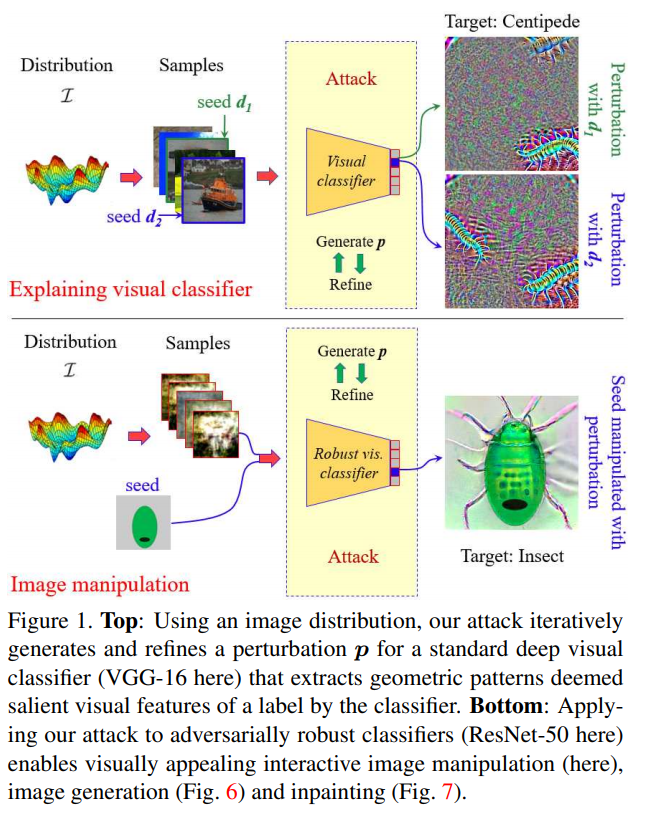
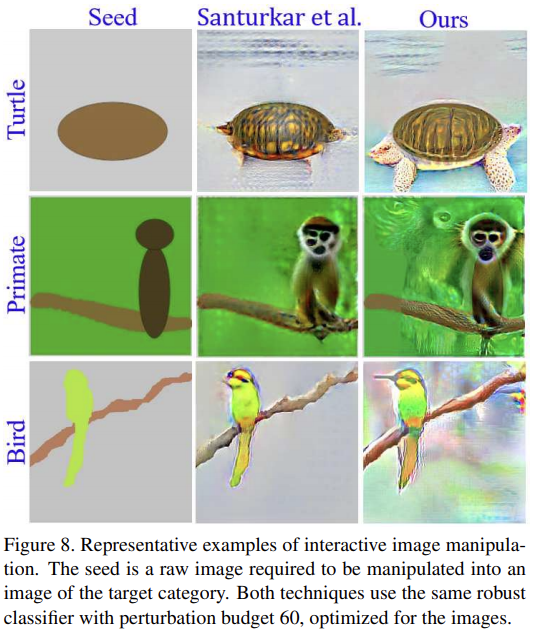
| [논문 리뷰] Attack to explain Deep Representation (0) | 2021.01.04 |
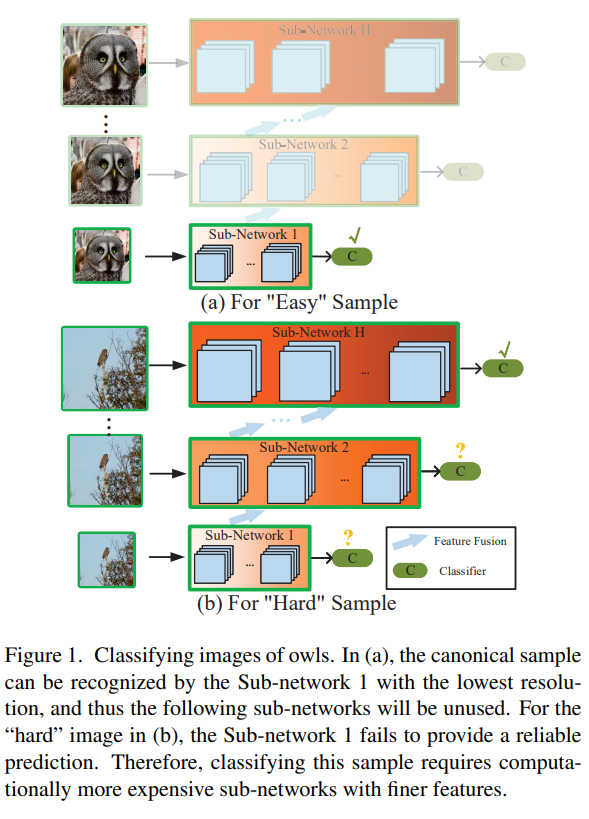
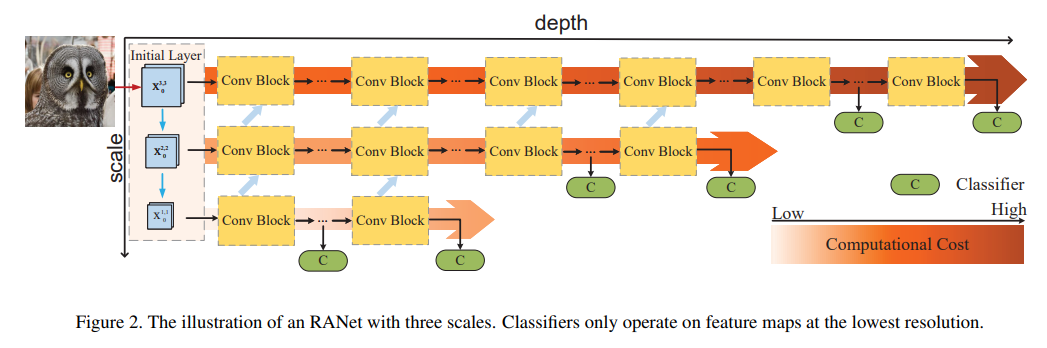
| [논문 리뷰] Resolution Adaptive Networks for Efficient Inference in CVPR2020 (0) | 2020.07.06 |
| [논문 리뷰] SSD :Single Shot MultiBox Detector (3) | 2019.08.13 |