Revisiting ResNets: Improved Training and Scaling Strategies
I. Bello W. Fedus X. Du E. Cubuk ...
Abstract
Novel Computer vision architecture들은 spotlight를 독점하지만, 모델 구조의 영향력은 보통 학습 방법과 scaling strategies의 변화와 함께 융합된다. 본 논문은 ResNet을 가지고 3가지 측면에서 위의 내용을 풀어낸다. 놀랍게도, training과 scaling 전략들이 구조를 바꾸는 것보다 더 좋은 결과를 가져왔다. 최고의 성능을 가지는 scaling strategy를 보여줄뿐만 아니라, 2가지의 새로운 scaling strategies를 제안한다. 1) overfitting이 발생할 수 있는 영역에서 model depth scaling. 2) 추천된 방법이 아닌 좀 더 느리게 image resolution을 증가시키는 것.
본 논문에서는 ResNet을 개선하여 ResNet-RS를 제안한다. TPU에서 EfficientNet보다 1.7~2.7배 더 빠르며 비슷한 정확도를 가지며 large-scale semi-supervised learning setup에서 Top-1 86.2%의 정확도를 가진다. 본 저자들은 새로운 ResNet을 실제로 사용하는 것을 추천한다.
1. Introduction
vision model의 성능은 모델구조, 학습 방법과 scaling 전략의 생성물이다. 하지만, 최근 연구들은 구조 변경만 강조하며, novel architecture들이 많은 발전의 기초가 되지만 동시에 학습 방법과 hyperparameters들을 변경해야하는 부분들이 있다. 최신의 학습방법으로 새로운 구조를 학습한 것들도 때지난 학습방법으로 오래된 구조와 비교를 자주한다. (ResNet과의 비교). 본 논문은 유명한 ResNet 구조의 학습방법과 scaling 전략의 영향력에 대해 연구한다.

먼저, ResNets에 적용된 최근 학습방법과 정규화 방법에 대해서 조사했으며 표 1에서 볼 수 있다. 학습방법 사이의 상호작용을 발견했으며, 여러개의 정규화 기술을 사용할 때, weight decay value를 줄이면 이득을 보는 것을 확인했다. 표 1에서도 확인할 수 있는데, 개선된 학습 방법으로 약 3%의 성능 상승을 확인했으며, 2개의 작고 공통적인 구조인 ResNet-D와 Squeeze-and-Excitation을 추가해 성능 상승을 확인했다.

본 논문에서는 철저하게 scaling rule들을 정해 진행했는데, 모든 학습 기간을 철저하게 지켰다. (10 epoch 대신에 350 epoch 사용). 여기서, 저자들은 모델크기, 데이터셋 크기, epoch의 수와 같은 scaling strategy와 학습 영역과 최고 성능 사이의 의존성을 발견했다. 또한, 이러한 의존성은 작은 영역에서는 누락되었으며 이것은 sub-optimal이 나타나게했다. 따라서, 저자들은 새로운 scaling stragies를 제안했으며, 1) overfitting이 발생할때는 depth를 늘리는 것을 멈추고 width를 늘리기 2) image resolution을 천천히 증가시키기 이다.
이러한 학습 및 scaling strategies를 사용해 ResNet-RS를 만들었으며, EfficieintNet보다 더 빠르고 성능이 좋다. 특히, large-scale semi-supervised learning setup에서는 더 큰 차이를 보였다.
마지막으로, 개선된 training과 scaling strategis의 전략의 일반성을 테스트하는 일련의 실험으로 마무리한다. 먼저 저자들의 방법으로 EfficieintNet-RS를 만들어 일련의 downstream takss에서 최신의 self-supervised algorithms (SimCLR SimCLRv2)와 비교했으며, video classification으로도 확장이 가능하다. 약 3D-ResNets으로 Kinetics-400 dataset에 대해 약 4%의 성능 향상을 보았다.
Contributions
- 정규화 기술와 그것들의 상호작용을 실험을통해 최적의 상태를 찾았으며 이것은 모데 구조 변경없이 이뤘다.
- 쉬운 scaling stragy를 제안함.1) overfitting이 발생할때는 depth를 늘리는 것을 멈추고 width를 늘리기 2) image resolution을 천천히 증가시키기
- ResNet-RS: TPU에서는 EfficientNet보다 1.7~2.7배 GPU에서는 2.1배~3.3배 더 빠르다.
- Semi-supoervised training에서 EfficientNet-NoisyStudent보다 TPU에서 4.7배 (GPU에서 5.5배) 더 빠르며 86.2%를 달성함.
- self-supervised representations(Sim-CLR와 SimCLRv2)에서도 좋은 성능을 보임.
- 3D resNet-RS로 video classification으로 확장을 했으며, baseline보다 약 4.8% 성능 향상을 보임.
2. Characterizing Improvements on ImageNet
AlexNet이후로 image recognition 분야는 발전해왔는데 크게 4가지 분야로 발전되었다. 네트워크 구조, 학습/정규화 방법론, scaling strategy 그리고 추가적인 학습 데이터 사용
Architecture. novel architectures이 큰 관심을 받아왔다. AlexNet을 시작으로 최근에는 NAS를 활용한 네트워크들이 있다. 또한, adapting self-attention을 visual domain에 적용하여 이미지 분류 를 위한 ConvNets에 영향을 주거나 lambda layers와 같은 대안을 사용하는 방법들도 있다.
Training and Regularization Methods. ImageNet의 등장은 학습과 정규화 접근의 혁신을 앞당겼다. dropout, label smoothing, stochastic depth, dropblock 그리고 data augmentation과 같은 정규화 방법이 있으며, learning rate schedules로 정확도를 개선한 방법들도 있다. 하지만, RegNet과 같이 작은 데이터셋에서는 좋은 성능을 보이지만, ImageNet과 같은 큰 데이터 셋에서 좋은 성능을 보이는지 확인하지않은 연구들도 있으며, 작은 데이터셋에서 성능이 좋다고 해도 더 큰 규모에서 개선이 있는지 불분명하다.
scaling Strategies. 모델의 dimensions (width, depth and resolution)을 증가시키는 것은 확실히 성능 향상을 기대할 수 있다. NLP 영역의 GPT-3나 Switch Transformer의 성능 향상이 이를 증명 했으며, 비슷하게 computer vision 분야에서도 유용성을 증명했다. ResNet 같은 경우 depth를 증가시키며 width를 증가시킨 논문들도 있다. 최근 학습 budgets이 증가함에 다라 resolution을 600이나 448로 사용하는 논문들도 있으며, 이것을 compound scaling rule로 체계화한 EfficientNet이 있다. 그러나, 이러한 scaling strategy는 ResNet 뿐만 아니라 EfficientNet 또한 sub-optimal에 도달하도록 한다.
Additional Training Data. 추가적인 데이터를 학습에 사용하여 정확도를 올리는 방법은 유명하다. 최근에는 130M개의 unlabeled images에 psuedo-labels를 사용해 정확도를 올린다. Meta pseudo-labels는 semi-supervised learning technique의 개선된 방법인데, ImageNet에서 약 90% 성능을 가져왔다. 이는 ResNet-RS에도 적용했으며 밑의 표4에서 확인할 수 있다.

3. Related Work on Improving ResNets
개선된 학습방법과 구조 변경을 통해 성능향상은 항상 이뤄져왔다. stem과 downsampling block을 수정하는 반면 label smoothing과 mixup을 사용한 논문들도 있다. 또한, SE block 추가, selective kernel, 그리고 anti-alisa downsampling을 사용한 논문도 있다. 최근에는 여러 구조 변경과 개선된 학습 방법으로 EfficientNet-B1~EfficientNet-B5까지 따라잡은 연구도 있다.
위의 연구들은 scaling strategies에 신경을 쓰지않는 반면 본 논문은 조그마한 구조 변경과 training/scaling strategies에 집중한다. 따라서, 앞서 언급한 방법들과 매우 다른 방법이며, 추가적인 요소로 예측한다.
4. Methodology
4.1 Architecture
크게 2가지의 구조 변경이 있는데, ResNet-D와 모든 bottleneck에 SE Block을 추가하는 것이다.
ResNet-D은 총 4가지의 수정사항이 있다.
1) Inception-V3와 같이 stem의 $7\times7$ convolution을 3개의 $3\times3$으로 변경한다.
2) downsampling blocks의 residual path에서 처음 2개의 convolution에 대한 stride size 전환
3) downsampling blocks의 skip connection path에서 stride-2 $1\times1$ convolution을 $2\times2$ average pooling과 non-stride $1\times1$ convolution으로 바꾼다.
4) stride 2 $3\times3$ max pool layer를 제거하고 그 다음 bottleneck block에 $3\times3$ convolution을 추가한다.
밑의 그림 6에서 변경 사항을 확인할 수 있다.

Squeeze-and-Excitation은 전체 feature map에서 average pooling signals로 cross-channel interactions을 통해 channel의 가중치를 재설정하는 것이다. 하지만, 본 논문에서 SE block을 쓰지 않은 경우도 있으며 따로 명시해두었다.
4.2 Training Methods
정규화와 data augmentation methods에 대한 연구이다.
Matching the EfficientNet Setup. 350epoch을 쓰는 것 처럼 EfficientNet의 학습 방법과 비슷하지만 다른점이 3가지가 있다. 1) cosine learning rate schedule 사용(<-> exponential decay) 2) RandAugment 사용 (<-> autoAugment) 3) Momentum optimizer (<-> RMSProp)

Regularization weight decay, label smoothing, dropout 그리고 stochastic depth를 사용함. Dropout의 경우 마지막 layer에서 grobal average pooling이후 출력에서 사용함. Stochastic depth는 층의 깊이에 따라 특정 확률로 각 layer을 제거하는 기술이다.
Data Augmentation. RandAugment를 사용하며, 일련의 random image transformations로 data augmentation을 적용한다. AutoAugment보다는 성능이 조금 더 좋다.
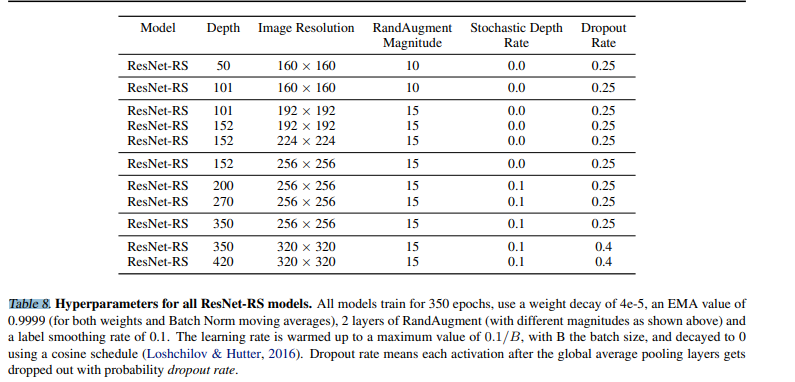
Hyperparameter Tuning. 본 논문에서는 ImageNet training set의 2%를 held-out validation set으로 사용하며, minival-set과 validation-set이 존재한다. 하이퍼 파라미터는 밑의 표 8에서 확인할 수 있다.
5. Improved Training Methods
5.1 Additive Study of Improvements
ResNet-200은 기본적으로 79.0%의 정확도를 가지는데 개선된 학습 방법을 사용하면 82.2% (+3.2%)의 향상이 있으며, SE block과 ResNet-D를 사용하면, 83.4% 까지 상승한다. 개선 된 학습 방법으로 3/4의 성능 향상을 볼 수 있었다.
5.2 Importance of decreasing weight decay when combining regularization methods
table 2는 여러 정규화 방법을 조합하여 사용할 때, weight decay를 바꾸는 것에 대한 중요성을 보여준다.

보는 것과 같이 RandAugment와 label smooting만 사용했을 때는 괜찮지만 더 추가적인 방법을 적용하면, 오히려 성능이 떨어진다. 직관적으로, weight decay가 regularizer로 사용됨을 알 수 있다. 최근 논문에서 추가적인 data augmentation은 가중치의 L2 norm을 감소시킨다고 주장하는 논문도 있으며, 여러 논문에서 더 작은 weight decay를 사용하면 성능이 올라감을 나타낸다.
6. Improved Scaling Strategies
multipliers에 따라 다르게 학습을 시켰다. Appendix E 에서 확인할 수 있다. width = [0.25, 0.5, 1.0, 1.5, 2.0] depth = [26, 50, 101, 200, 300, 350, 400] Resolution = [128, 160, 224, 320, 448] 을 적용했다.
FLOPs do not accurately predict performance in the bounded data regime (FLOPs은 제한된 데이터 영역에서 성능을 정확하게 평가할 수 없다.)

위의 그림에서 보이는 것처럼 작은 모델은 error와 FLOP 영역 사이에 어떤 법칙이 있는 것 처럼 보인다. 하지만, 더 큰 모델에서는 그 법칙이 소용이 없어진다. 즉, 무조건 크다고 좋은 성능을 가져오는 것이 아님을 확인할 수 있다. 따라서, 원하는 FLOPs내에서 정확한 scaling configuration이 필요하다.
The best performing scaling strategy depends on the training regime. (최고 성능 scaling strategy는 학습 체제에 따라 다르다.)
따라서, FLOPs에 따른 정확도 비교가 아닌 speed-accuracy Pareto curve을 사용한다. 그림 3에서 확인할 수 있다.

위의 그림을 보면 확연하게 최고의 성능을 가지는 scaling을 확인할 수 있다.
6.1 Strategy #1- Depth Scaling in Regimes Where overfitting can Occur
Depth scaling outpeforms width scaling for longer epoch regimes. (긴 epoch에서는 width scaling보다 depth scaling이 더 나은 성능을 보인다.)
그림 3의 right를 보면, width scaling에서 성능 저하가 나타난다. 이것은 overfitting을 뜻하는데, width scaling이 더 많은 파라미터를 사용하기 때문이다. 즉, depth scaling은 width scaling보다는 적은 파라미터 증가를 가진다.
Width scaling outperforms depth scaling for shorter epoch regimes. (더 짧은 epoch에서는 width scaling이 더 나은 성능을 보인다.)
반대로, 그림 3의 left를 보면, width scaling에서 더 좋은 성능을 보인다. 또한, 그림 3의 middle을 보면, depth scaling과 width scaling이 서로 다르게 차이나는데 input resolution에 따라 다른다. 이와 같은 결과는 training 영역에서 scaling strategy가 항상 같은 규칙을 가지지않음을 보인다. 이는 과거의 연구들에서도 비슷한 결과를 보이는데, 더 짧은 epoch에서는 너비를 조정하는 것이 바람직하다는 실험 결과와 일치한다.
6.2 Strategy #2 - Slow Image Resolution Scaling
위의 그림 2를 보면 더 큰 image resolutions는 오히려 성능이 감소한다. 따라서, 과거의 연구들은 600 심지어 800의 resolution을 가지지만, 이거와 반대로 천천히 증가시켜야한다고 생각한다. Section 7.2에서 더 자세히 설명한다.
6.3 Two Common Pitfalls in Designing Scaling Strategies
scaling strategy에 대한 연구로 과거의 scaling straegy에 대한 2가지 헛점을 발견했다.
(1) Extrapolating scaling strategies from small-scale regimes. 작은 모델이나 작은 epoch에서 만든 scale rule은 잘못되었다고 생각하며, 일반화가 덜 된 것으로 판단한다. 과거의 연구들은 작은 모델 또는 짧은 training epochs로 scaling rules를 주장햇는데, 이것은 best performing scaling strategy와 training regime 사이의 의존성을 누락시켰다. 즉, 더 큰 모델이나 epoch에서는 scaling rule이 깨진다.
(2) Extrapolating scaling strategies from a single and potentially sub-optimal initial architecture. (최적화되지 않은 single initial architecture에서 scaling strategies 추정) 최적화 되지 않은 초기 구조로 부터 시작하는 것은 scaling results를 삐뚤어지게할 수 있다. 예를들어, EfficientNet-B0는 고정된 FLOPs와 resolution에서 찾은 네트워크 구조인데, 이것은 거기에 해당하는 FLOPs와 resolution에 국한되어 있다. 반대로 본 논문은 다양한 widths, depths 그리고 resolution에서 디자인했다.
6.4 Summary of Improved Scaling Strategies
새로운 task를 할 때, 모델을 다른 scales에 따라 작은 subset으로 나눠 full training epochs로 실행하는 것을 추천한다. 물론, cost가 많이 들지만, 제일 좋은 architecture을 찾을 수도 있다.
이미지 인식 분야를 위해 scaling stategies는 1) overfitting 발생 전까지 depth를 늘리고 2) resolution을 천천히 키우는 것이다. 이러한 방법으로 ResNet-RS와 EfficientNet-RS를 발견했다. 비슷한 사례로 LambdaResNets와 NFNets가 있다.
7. Experiments with Improved Training and Scaling Strategies
7.1 ResNet-RS on a Speed-Accuracy Basis
개선된 training and scaling strategies를 사용해 ResNets을 재디자인한 ResNet-RS를 만들어 냈다. 그림 4에서 보는 것 처럼 speed와 accuracy가 훨씬 빠르다.
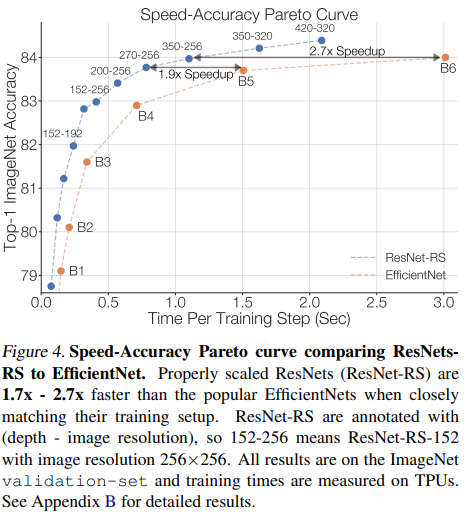
FLOPs vs Latency.(작은 파라미터와 크기를 가진 네트워크가 왜 더 느린가?) 예전부터 FLOPs가 실제로 학습및 평가 지연시간 측정을 하지못한다는 논문이 나왔따. 즉, FLOPss가 poor proxt라는 것이다. FLOP은 연산이 종종 메모리 접근 비용에 의해 제한되고 최신 행렬 곱 단위에서 다양한 수준의 최적화를 가지기 때문에 특히 좋지 않은 proxy이다. inverted bottleneck을 사용한 EfficientNet은 큰 활성화함수와 함께 depthwise convolutions을 실행하고 따라서 작은 활성화와 함께 dense convolution인 ResNet의 bottleneck 구조보다 메모리당 계산 비율이 적을 수 밖에 없다. -> 아마도... depthwise 방법은 한 depth당 메모리 access가 필요해서 실제로 지연시간을 줄인다는 것 같다. 밑의 표3은 이러한 부분을 나타내는 표이다.
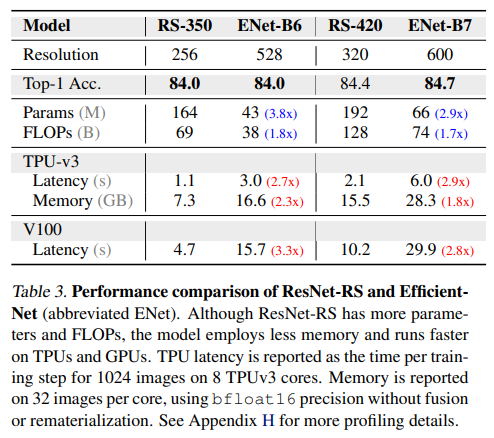
Parameters vs Memory Memory가 활성화 크기에 의해 결정되는 경우가 많기 때문에 prarameters 개수가 반드시 학습 중 메모리 소비를 나타내는 것은 아니다. 따라서, 더 큰 activation을 가진 EfficieNet이 3.8배 적은 파라미터를 가지지만 2.3배 느린 잉이다. 따라서, 메모리 소비량과 지연시간이 스프트웨어 및 하드웨어 스택과 밀접하게 연결되어 있음을 강조한다.
7.2 Improving the Efficiency of EfficientNets
Section 6에서 말했던 image resolution이 성능을 저하시키는 것에 대한 분석이다. EfficientNet은 depth, width 그리고 resolution이 독립적으로 사용하여 sub-optimal에 도달한 것이다. 따라서, width와 depth를 바꾸지 않고 여러 resolution을 사용해 여러 version을 만들어 학습했다. RandAugement를 10: <=224 15: 224< R < 321 20: 320 > 로 사용했으며, 그림 5에서 re-scaled EfficientNets이 더 좋은 성능을 보임을 나타낸다.

7.3 Semi-Supervised Learning with ResNet-RS
ResNet-RS를 large scale semi-supervised learning setup에 적용하면 어떤가로 실험을 진행함. Noisy Student와 비슷하게 1.2M labeled ImageNet images와 130M pseudo-labeled images로 섞은 데이터셋으로 학습을 했다. 그렇게 한 결과는 밑의 표4에 나타나며, 성능은 비슷하며 속도에서 매우 큰 이점을 가진다.

7.4 Transfer Learning of ResNets-RS
최근 self-supervised learning algorithms이 transfer learning performance를 능가했다고 주장한다. 하지만, supervised learning에 비해 설정이 어렵다. SimCLR와 SimCLRv2와의 비교를 위해 실험을 진행했는데, 논문에서 제안하는 방법을 조금 바꿨다.
- Rand Augmentation, label smoothing, dropout, decreased weight decay, cosine lerning rate decay, 400 epoch
- No using stochatic depth or EMA
- No using ResNet-D and SE block
위의 제한을 걸어둔 것은 SimCLR: 긴 학습, data augmentation 그리고 temperature parameter for their contrastive loss와 architecture를 맞추기 위해서 이다.
밑의 표 5는 결과를 나타낸다.
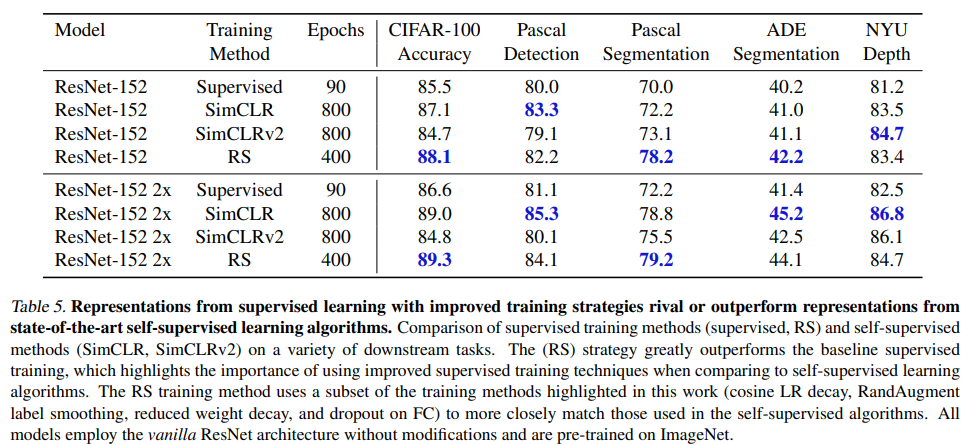
보는 것처럼 ResNet이 더 좋은 성능을 보이며, 이는 self-supervised algorithms이 supervised보다 더 많은 universal representations을 가진다는 것에 반박할 수 있다.
7.5 Revised 3D ResNet Video Classification
나중에
8. Discussion
Why is it important to teas apart improvements coming from training methods vs architecures? (학습 방법과 구조를 구분하면 좋은 이유) 학습 방법이 네트워크 구조보다 task-specific하다. 즉, 더 좋은 학습 방법으로 새로운 구조를 쌓는 것이 더 일반적이라는 것이다.
How Should one compare different architectures? 학습 방법과 확장은 일반적으로 성능을 증가시키므로, 서로 다른 네트워크 구조를 비교할 때 두 측면 모두 제어하는것이 중요하다. 따라서, FLOPs와 parameters보다 latency와 memory consumption을 사용하는 것이 더 일반적일 것이다.
Do the improved training strategies transfer across tasks? domain과 dataset 크기에 따라 다르다. 여기서 사용된 많은 학습/정규화 방법은 large-scale pre-training에서는 사용되지 않는다. data augmentation 또한 작은 데이터셋 또는 큰 epochs에서 유용하며, 특정 augmentation 기법은 task의존적이다.
Do the scaling strategies transfer across tasks? section 6에서 보는 것과 같이 350 epoch에서는 depth가 10epoch에서는 width가 더 좋은 성능을 보였다. 즉, 최고 성능 scaling strategy는 학습 방법과 overfitting 유무에 따라 다르다. 저자들은 resolution을 늘리는 것에 대해서도 확신을 하지 못했으며 future work로 남겨둔다.
Are architectural changes useful? 당연히 좋지만, 학습 방법이나 scaling strategies가 더 큰 영향력을 가진다. 그 이유는 네트워크 변경은 너무 복잡하고 느려질 수 있기 때문이다. 나중에는 hardware 친화적인 네트워크 구조가 나오기를 기대한다.
How should one allocate a computational budget to produce the bset vision models? 먼저, 하드웨어 효과적으로 사용할수 이는 쉬운 네트워크부터 시작하여 점차 다른 resolution, depth, 그리고 width를 Pareto curve에 맞춰 적용해야한다. 이는 NAS와는 다른데, NAS는 너무 제한된 환경에서 네트워크 구조를 찾으며, RegNet은 단지 10 epoch만은 사용한다.
9. Conclusion
향상된 scaling 전략과 최신의 학습 방법으로 resNet 구조의 놀라운 duration을 보여주었다. 저자들은 자신들이 주장하는 바에 대해 더 많은 연구를 하기를 장려한다.