Resolution Adaptive Networks for Efficient Inference
Le Yang Yizeng Han Xi chen Shiji Song Jifeng Dai Gao Huang
Tsinghua University, BNRist, HIT, SenseTime
Abstract
Adaptive inference(조정가능한 추론?실험?)은 동적으로 정확도와 계산량을 tradeoff 할 수 있도록하는 효과적인 메커니즘이다. 현재 존재하는 works은 네트워크의 높이와 너비를 불필요한 구조를 사용한다. 따라서, 본 논문은 입력에서 공간의 불필요한 반복에 집중했으며, Resolution Adaptive Network(RANet)을 제안한다. 본 논문은 쉽게 분류 가능한 것들은 원형의 feature들 만으로 충분하지만, 분류가 힘든 것들은 공간적인 정보가 더 필요하는 것에 착안했다. 즉, 입력단에서 충분히 예측가능한 것들은 바로 출력으로 가는 것이다. 그 동안에, 분류가 힘든 것들은 큰 해상도를 유지하면서 네트워크를 통과해 간다.
1. Introduction
하드웨어의 발전으로 ResNet이나 DenseNet과 같이 높은 계산량을 요구하는 Deep CNN이 나왔지만, 비용이 너무 많이 든다. 이런 점을 보완하기 위해 lightweight network, network pruning, weight quantization 이 나왔다. 그 중에서 adaptive inference scheme이라는 개념은 불필요한 반복을 하는 계산량을 줄이기 위해 쉬운 샘플을 동적으로 네트워크 구조에 적용하거나 각 입력에 조건부로 파라미터를 사용해 놀라운 성능을 보였다.
최근 adaptive inference에 대한 논문들은 너비와 높이를 줄여나가는 방향으로 하고 있다. 이것은 본래의 분류가 어렵다는 것을 보여주고 있다. 작은 모델로도 정확하게 분류하는 구조가 있는가 하면, 더 큰 구조가 필요한 경우도 있다. 23은 실행 시간 동안 강화학습으로 학습한 policy에 의거해 pruning을 실시하며, 36은 convolutional layer 전에 linear layer을 추가해서 binary decision을 실시한다. Multi-Scale Dens Network(MSDNet)은 보조의 분류기를 사용해 어떤 샘플들은 빠르게 분류되도록 한다.
기존에 존재하는 논문들은 네트워크 구조에서 계산량의 불필요한 반복을 줄이는데 집중을 했지만 본 논문은 데이터 샘플에서 정보의 불필요한 반복을 줄이는데 집중한다.
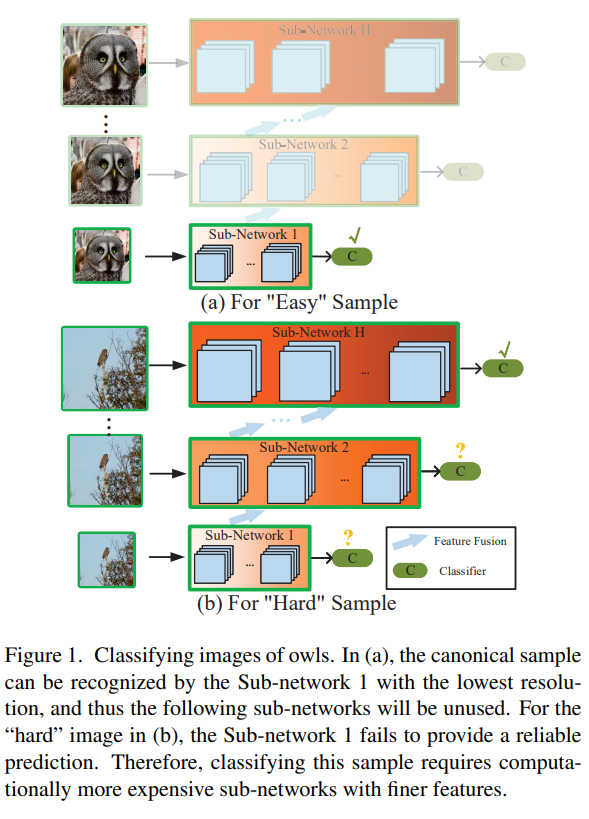
즉, 사진의 (a)처럼 쉬운 샘플은 낮은 해상도에서 해결하고 (b)처럼 어려운 샘플은 고해상도에서 해결하는 것이다.
위의 fig1은 직관적으로 RANet을 이해할 수 있다. 쉽게 판별이 되는 것은 작은 sub-network에서 끝나며, 판별이 어려운 것은 점점 더 고해상도에 해당하는 sub-network로 판별하며, 전의 sub-network에서 사용한 정보를 재사용한다. 여기서, 불필요한 convolution을 제거하면서, 계산량의 효율을 증가시킨다.
CIFAR-10,100, ImageNet에 대한 이미지 분류를 실행했으며, 11에서 손쉽게 adaptive inference task를 실시할 수 있다.
2. related work
Efficient inference for deep networks.
network inference 속도를 늘리기위해, 가벼운 모델을 디바인 하거나, pruning 하거나, quantizing network 만들었다. 게다가, knowledge distilling 이라는 기법으로 작은 네트워크가 더 큰 네트워크를 따라하게 만드는 기법도 있다.
앞선 방법들은 지속적으로 전체 네트워크에 입력을 사용하지만, adaptive network는 전략적으로 입력 이미지 복잡도에 따라 적절하게 할당할 수 있다. 이러한 전략은 최근 각광받고 있다. ensemble model or 선택적 실행 model이 예시이다. 또한, skip layer/block을 사용하거나, 동적으로 channel을 선택하는 논문들도 있다. 그리고 auxiliary predictor(보조 예측기)를 사용하는 것도 있다. 게다가, 많은 가지를 가지는 구조를 사용해 동적으로 활용하는 논문도 있다.(35) 그러나 전의 논문들은 오직 네트워크 구조를 디자인 하는데만 치중하고 있으며 그래도 Drop an Octave와 같은 논문이 구조적/공간적 불필요한 반복을 활용했다고 할 수 있다.
Multi-scale feature maps and spatial redundancy.
다양한 scale의 인식에 사용하는 것이 성능 증가에 좋다는 것이 밝혀졌으며, 다양한 vision task에 활용되고 있다.
고해상도의 feature map을 유지하는 것이 특이한 샘플이나 구체적인 task가 요구되는 pose estimation에서 필수적이다. Drop an Octave에서 제안한 Octave convolution은 작은 scale에서의 feature map을 활용해 분류 성능과 계산 효율성을 동시에 증가시킨다.
하지만, 공간적 불필요한 반복(spatial redundancy)을 고려한 adaptive model은 없다. 본 논문의 RANet은 resolution adaptation을 통해 계산 효율성과 성능을 모두 개선했다.
3.Method
여기서 RANet 설명
3.1 Adaptive Inference Setting
일단, K개의 분류기가 존재한다. 다음의 수식은 입력 x에 대한 출력을 나타낸다.
는 k번째 분류기에 해당하는 파라미터
은 c번째 클래스에 대한 예측값이다. 또한
의 파라미터들은 공유된다.
입력의 복잡성에 따라 적정한 계산 리소스를 할당한다. 본 논문은 softmax를 사용하는데, 각 분류기의 softmax 값은 threshold 인
을 넘어야 다음 분류기로 가지 않는다. 밑의 수식은 위를 나타내는 것이다.
에 의해서 분류기 성능과 테스트시의 계산 비용이 trade-off 관계이다.
3.2 Overall Architecture
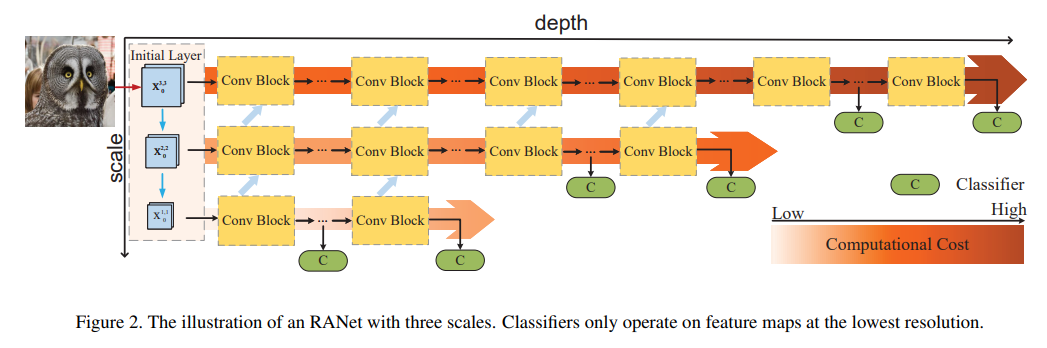
위의 그림은 RANet의 전체적인 구조이다. 이와 같은 multi scale structure은 11과 유사한데, 가장 다른 점은 low-resolution feature을 먼저 추출하는 것이다. 기존의 네트워크들은 high-resolution feature을 추출한다.
RANet의 기본적인 아이디어는 먼저, 가장낮은 해상도에서 feature map을 추출하는 것이다. 그리고 만약 분류 결과가 별로라면 다음 sub-network로 넘어가며 이 때, 전의 sub-network에서 사용한 feature map을 혼합해서 사용한다. 또한, 분류기는 마지막 block에서 2~3개만 가진다.
이와 같은 구조는 쉽게 분류되는 것은 저해상도에서 충분히 분류될 것이고, 분류가 어려운 것은 저해상도에 사용된 feature와 함께 고해상도로 올라가면서 분류가 된다.
3.3 Network Details
3.3.1 Initial Layer
H와 S에 의해 입력 이미지의 해상도가 결정되는 곳이다. H는 네트워크 안의 base feature 수를 뜻한다. 그리고 Conv Block은 BN, ReLU, stride=2 인 conv layer을 가진다. 만약 H=4, S=3 이라고하면, 가장 h=3,4와 같은 마지막 2개는 같은 해상도를 가질 것이다.
3.3.2 Sub-networks with Different Scales
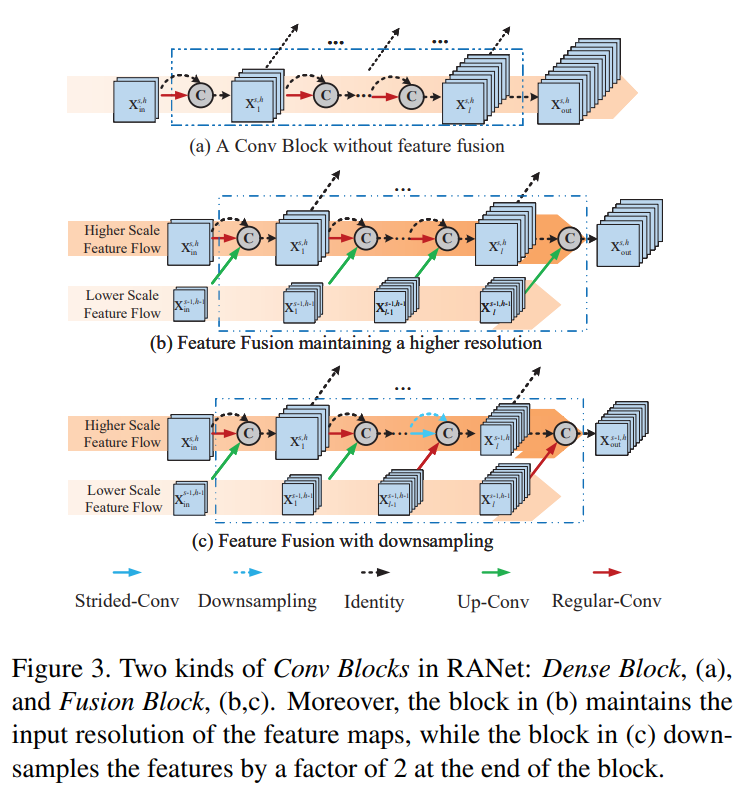
각 sub-networks들은 분리되어 다른 Conv Blocks를 가진다.
Sub-network 1.
그림 3(a)는 첫 sub-network를 제외하고는 전의 sub-network에서 온 feature를 사용하는 것을 보여준다. 그리고 각 feature map이 다음 sub-network로 가는데 DenseNet과 유사하다.
Sub-networks on larger-scale features.
그림 3(b,c)는 h>1인 경우 즉, 첫 sub-network 이후를 보여주며, 보는 것과 같이 전의 sub-network로 부터 feature map을 받으며 이 부분을 Fusion Blocks 라고 한다.
sub-network는 두 개의 fusion 방법이 있다. 첫 번째는 입력 해상도를 유지하는 것이고, 두 번째는 해상도를 줄여가는 것이다. 각각 fig3(b)와 (c)를 뜻한다. 그리고 Up-Conv layer에서는 bilinear interpolation(이중선형보간법)을 사용해 같은 해상도를 갖도록 하며 dense connection을 한다.
그리고 fig3(c)의 마지막을 보면, stride-Conv layer를 통해 해상도를 줄이고 sub-network로 부터 오는 feature map과 단순한 연결을 할 수 있도록 한다. 즉.. sub-network의 해상도에 맞춘다.
규칙이 있는데,
에서
까지는 모두 Fusion Blocks를 사용하고 나머지는 Dense Block을 사용한다. 또한,
은 feature map을 downsample하도록한다. 이와같은 처리는 sub-network 마지막 단(분류기가 있는 block)의 feature map이 가장 작은 저해상도를 갖도록 한다.
Transition layer.
transition layer을 추가해 feature map이 압축되도록 하며 계산 효율성을 가지도록 했다. 1x1 convolution operation with BN, ReLU를 만들어서!!
classifiers and loss function.
1~H까지 순서대로 cross-entropy loss function을 사용했다. 그리고 각 분류기에서 loss가 누적되도록 만들었다. 그리고 weight는 11을 따랐다.
3.4 Resolution and Depth Adaptation

위의 사진은 MSDNet과 RANet의 차이점이다. 일단, classifier가 각 sub-network에 존재하며, 전의 sub-network의 feature map을 사용한다. 그리고, 해상도와 depth adaptation이 자연스럽게 혼합되서 사용된다.
4. experiments
CIFAR, ImageNet에 대해서 실험을 진행했다.
Datasets.
그냥.. 통과ㅣ해도 될듯, 그냥 11처럼 CIFAR에서의 validation을 사용함.
Training policy.
하이퍼 파라미터 지정에 대한 내용. 공통적으로, SGD 사용, momentum 0.9, weight decay 0.0001 CIFAR batch size: 64, epoch: 300, learning rate: (0, 15, 225)(0.1, 0.01, 0.001) ImageNet batch size: 256, epoch: 90, learning rate: (0, 30, 60) (0.1, 0.01, 0.001)
Data augmentation.
CIFAR 32x32 randomly crop(After zero-padding), horizontally flip(p=0.5), RGB channel normalization(채널당 평균, 분산) ImageNet training에는 ResNet 따라서 실행. test에서는 224x224 center crop 실시
4.1 Anytime Prediction
prediction을 할 때, 모든 분류기를 사용했다.
Baseline models.
ResNet, DenseNet, Ensemble ResNet, Ensemble DenseNet을 포함했다. 그리고 RANet과 MSDNet의 경우 학습시 22를 참고해 추가했다고 한다.
Results.
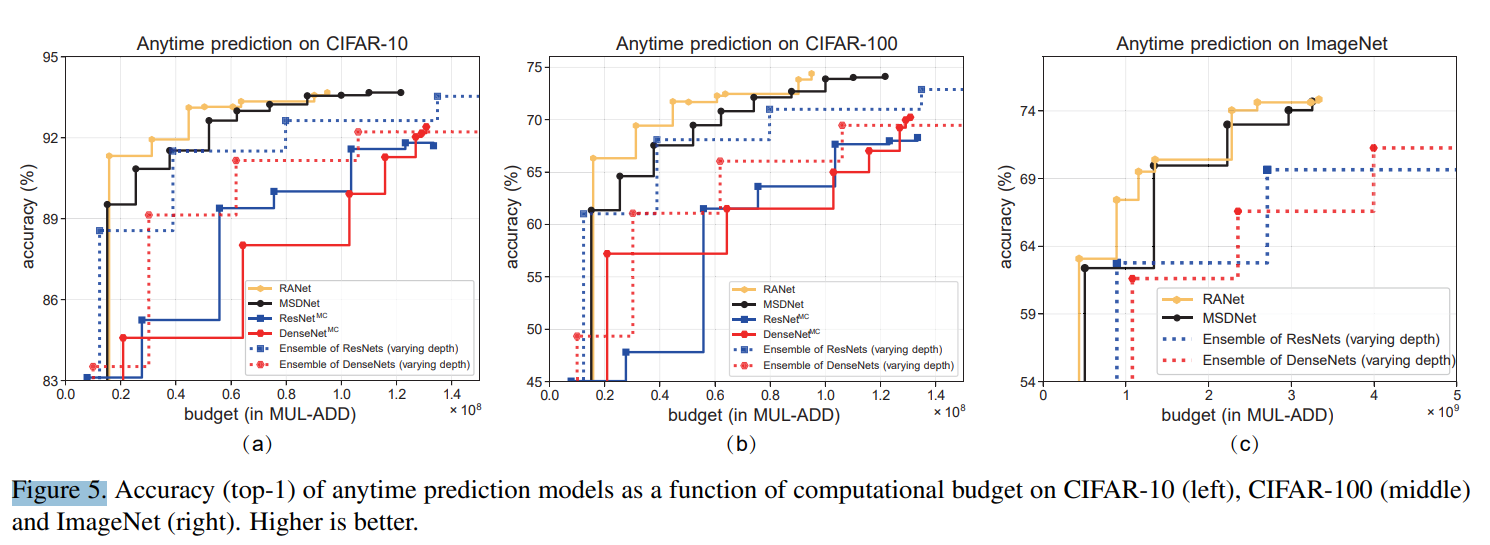
MSDNet과 RANet이 가장 좋은 성능을 보이며, RANet이 계산량이 적다. 그림을 보면 알 수 있는데, RANet이 적은 계산량으로도 높은 정확도를 보인다. 모든 데이터셋에서 RANet이 더 좋은 영향을 보여준다. 그리고 Ensemble ResNet과 다른 점은 전의 sub-network에서 사용한 feature map을 현재 sub-network에서 사용한다는 것이다. 따라서, 정확도와 더불어 계산량 감소에도 효과적이다.
4.2 Budgeted Batch Classifcation
thresholds(임계값)는 계산량에 따라 다르게ㅔ 설정해야한다. 만약 confidence가 임계값에 도달하면 예측결과를 내놓게 된다.
Baseline models.
그냥 어떤 네트워크를 사용했다에 대한 내용들이다. 특이점으로는 CIFAR에서 WideResNet, ImageNet에서 GoogLeNet을 사용한 것이다. 그리고 22를 참고해서 test에 사용 한 것.
Result.
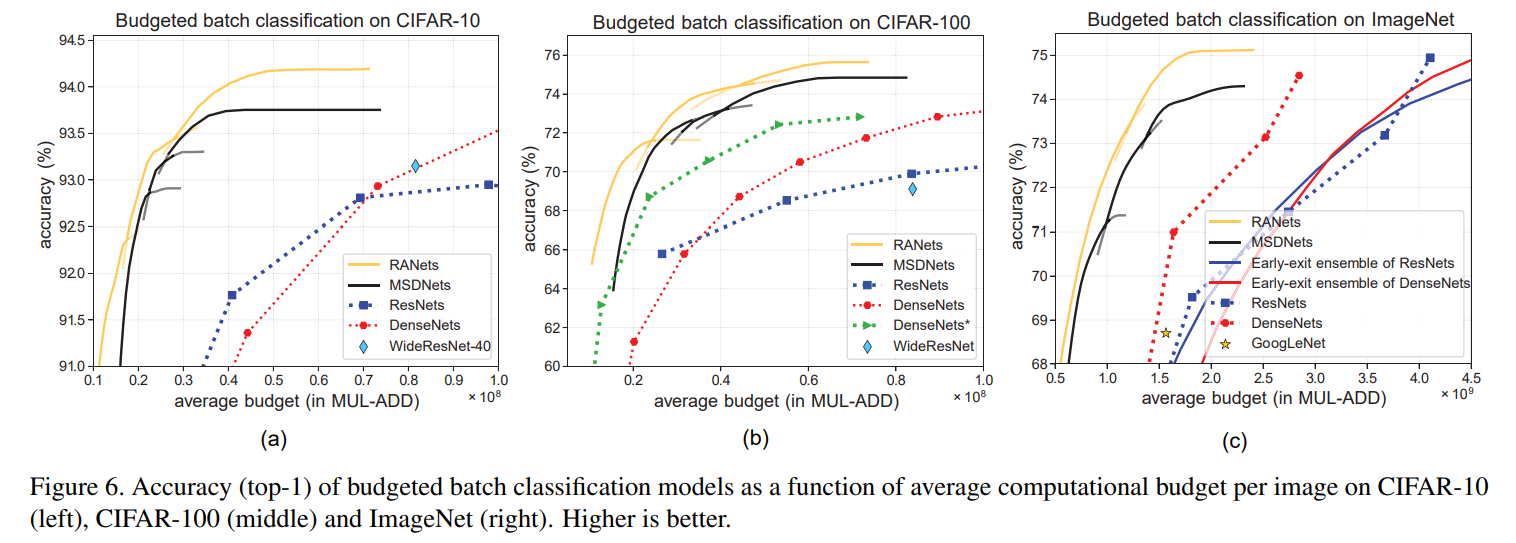
위의 결과 그림으로 보아 RANet은 적은 계산량으로도 높은 정확도를 가진다. 여기에는 결과에 대한 설명이 전부다 이다. 이런 결과를 미루어보아 RANet이 매우 뛰어난 성능을 보이는 것 같다.
4.3 Visualization and Discussion

위의 사진처럼 어려울 수록 더 뒷단의 sub-network에서 분류가 된다.
Multiple objects.
다양한 객체 사이에서도 좋은 성능을 보인다. fig7의 (a) 'hard' 중간은 사람들 사이에 부엉이가 있다. 이와같은 사진은 부엉이보다는 사람으로 인식할 가능성이 더 높다. 하지만, 사람의 관점에서는 사람들 보다는 사진의 중앙에 있는 부엉이가 더 중요한 정보라고 판단할 수 있으며, 이처럼 잘 분류하는 것이 강력한 네트워크라고 할 수 있다.
Tiny objects.
매우 작은 이미지에서 좋은 성능을 보인다. 작은 이미지는 downsampling 되면서 급속도로 정보가 사라진다. 이것은 fig7의 (b)를 보면 알 수 있다.
Objects without representative characteristics.
이미지에서 학습을 하는 것은 부분적인 특징으로 객체를 분류한다고 볼 수 있다. fig7의 (c)를 보면, 개의 얼굴이 보이지 않으면 인식이 어려운데, 이는 부분적인 특징(얼굴)로 객체를 분류하는 것으로 볼 수 있다. 고해상도 이미지를 사용하는 sub-network에서 충분히 부분적인 특징이 아닌 전체적인 특징으로 인식할 수 있다.
저해상도에서 구분이 가능한 것은 저해상도에 충분한 정보가 담겨진 것이고 분류가 힘든 것은 고해상도로 가면 더 많은 정보가 담겨져 있기 때문에 분류가 가능해진다.
5. Conclusion
결과적으로 RANet 이라는 가벼운 네트워크를 구축했으며, resolution adaptation과 depth adaptation을 통해서 계산 효율이 좋은 네트워크를 구축했다.
** 내얘기 ** 그렇다면 결국에는 고해상도로 갈 수록 좋은 성능을 보인다는 건데, 단지 resize를 통해서 고해상도로 만든다면 좋은 성능을 보일 수 있을까? 이게 궁금하네...
Supplementary
1. Appendix A : Implementation Details
1.1 CIFAR-10 and CIFAR-100
MSDNet :
scale(32x32, 16x16, 8x8) classifier(6, 8, 10) depth(16, 20, 24)
RANet:
3 종류의 base line이 있다. 3 또는 4개의 sub-network를 가진다.
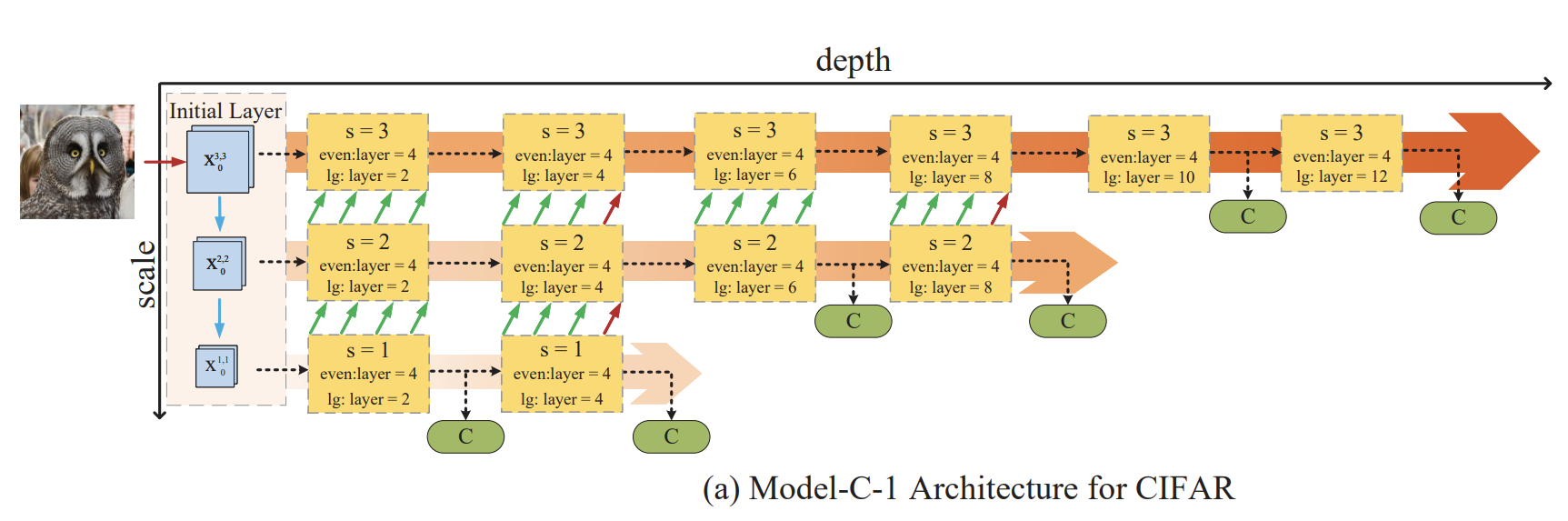
Model-C-1
1) even: 각 Conv Block의 layers 수. 여기선 4. 2) linear growth(lg): 각 sub-network마다 추가되는 Conv Block의 수. 여기선 2. 3) Channel numbers: 16, 32, 64. sub-network마다 입력 채널이 다르다. 4) 3 sub-network의 growth rate는 (6, 12, 24) 5) Fusion Block의 경우 현재 sub-network에서 75% 전 sub-network에서 25%를 가진다. 6) 총 6개 분류기를 가진다.
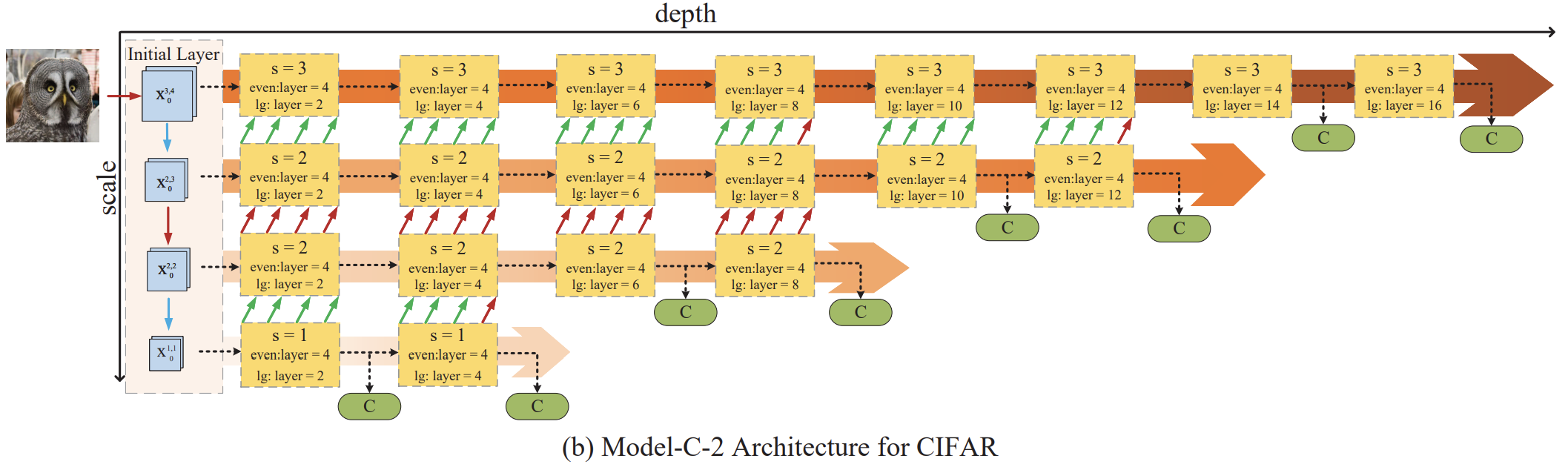
Model-C-2
1) Input Resolution: 32x32, 16x16, 16x16, 8x8 2) Conv Blocks 갯수: 8, 6, 4, 2 3) Input channel 수 : 16, 32, 32, 64 4) growth rate : 6, 12, 12, 24 5) 같은 resolution을 가지는 sub-network 사이에는 Up-conv Layers가 regular Conv Layers로 대체된다. 6) 총 8개 분류기를 가진다.
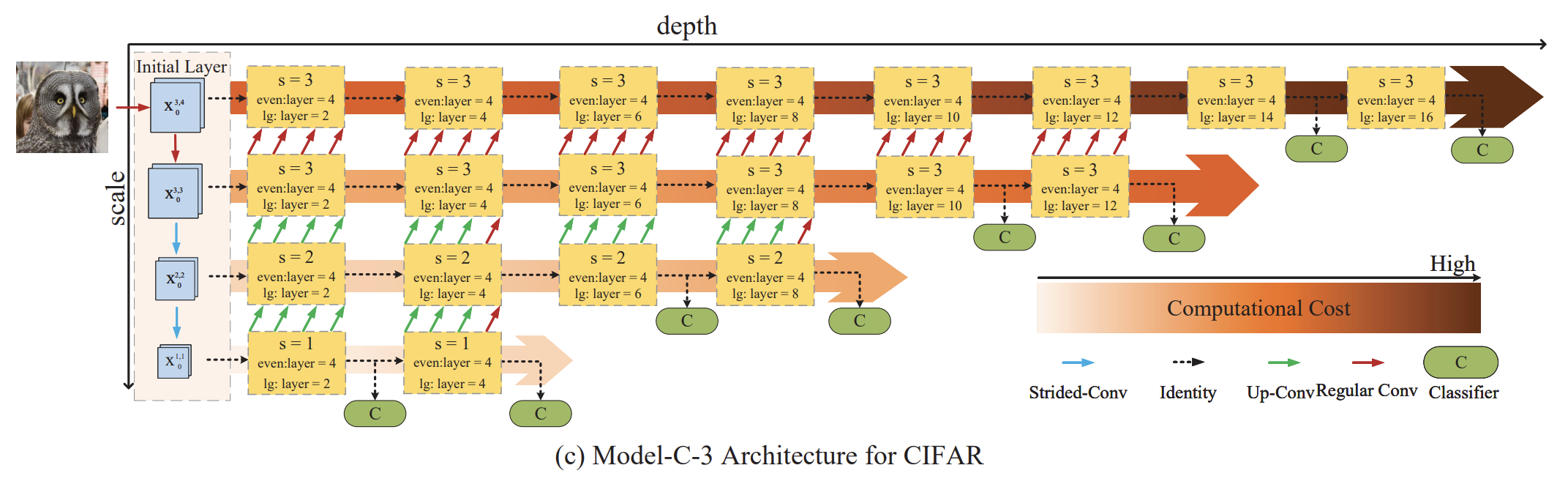
Model-C-3
1) Input Resolution: 32x32, 32ㅌ32, 16x16, 8x8 2) Conv Blocks 갯수: 8, 6, 4, 2 3) Input channel 수 : 16, 16, 32, 64 4) growth rate : 6, 6, 12, 24 5) 같은 resolution을 가지는 sub-network 사이에는 Up-conv Layers가 regular Conv Layers로 대체된다. 6) 총 8개 분류기를 가진다.
1.2. ImageNet
1) Input Resolution: 56x56, 28x28, 14x14, 7x7 2) Conv Blocks 개숫: 8, 6, 4, 2 3) Input channel 수 : 32, 64, 64, 128 4) growth rate : 16, 32, 32, 64 5) conpress factor: 0.25 6) Model 1과 Model2가 있는데, model2의 input channel 수가 64, 128, 128, 256 이다.

'공부 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Dynamic Feature Learning for Partial Face Recognition (0) | 2021.02.02 |
|---|---|
| [논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.01.13 |
| [논문 리뷰] Attack to explain Deep Representation (0) | 2021.01.04 |
| [논문 리뷰] SSD :Single Shot MultiBox Detector (3) | 2019.08.13 |
| [논문 리뷰] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (0) | 2019.07.19 |