Attack to Explain Deep Representation
[
Attack to Explain Deep Representation - IEEE Conference Publication
ieeexplore.ieee.org
](https://ieeexplore.ieee.org/document/9156888)
Mohammad A. A. K. Jalwana Naveed Akhtar M. Bennamoun A. Mian
University of Western Australia
Abstract
Deep visual model들은 입력 이미지의 극히 작은 변화에도 민감하다. 따라서, 본 논문에서는 모델을 공격해 바보처럼 만드는 것이 아닌 학습된 representation을 설명하는 것에 집중하는 첫 논문이다. 처음의 작은 변화가 나중에는 눈에 띄일 정도로 커지는 것을 확인할 수 있다. 본 저자들은 이러한 변화를 robust classifier에 공격을 함으로써 이미지 생성, 인페이팅 그리고 interactive image manipulation에 적용했다.
1. Introduction
deep model들은 적대적인 작은 변화에 대해서 취약하다. 특히, 사람이 인지못하는 추가적인 작은 신호를 통한 변화에도 약하다.
두 가지의 접근법이 있다.
1) 작은 변화를 생성하거나 높은 전도성을 통해 deep models을 멍청하게 만드는 것
2) 작은 변화에 반대해서 model을 방어하는 것
또한, 합성을 통해 적대적으로 robust한 network를 만드는 논문도 있다. -> 이건 꼭 보기[41]
[19]에서는 ImageNet과 같이 큰 데이터셋에서 사람이 인지하지못하고 불안정하지만 예측할 수 있는 feature들이 있다고 인정했다. 이렇게 non-robust feature에 의존적인 deep model들은 당연히 작은 변화에 민감할 수 밖에 없다. 이런 것을 미루어보아 사람의 인지와 deep visual representation 사이에는 큰 차이가 있는 것 같다. 따라서, [14]에서는 robust optimizer framework를 제안했지만, 기존의 것보다 계산량이 급격한 증가를 보인다.
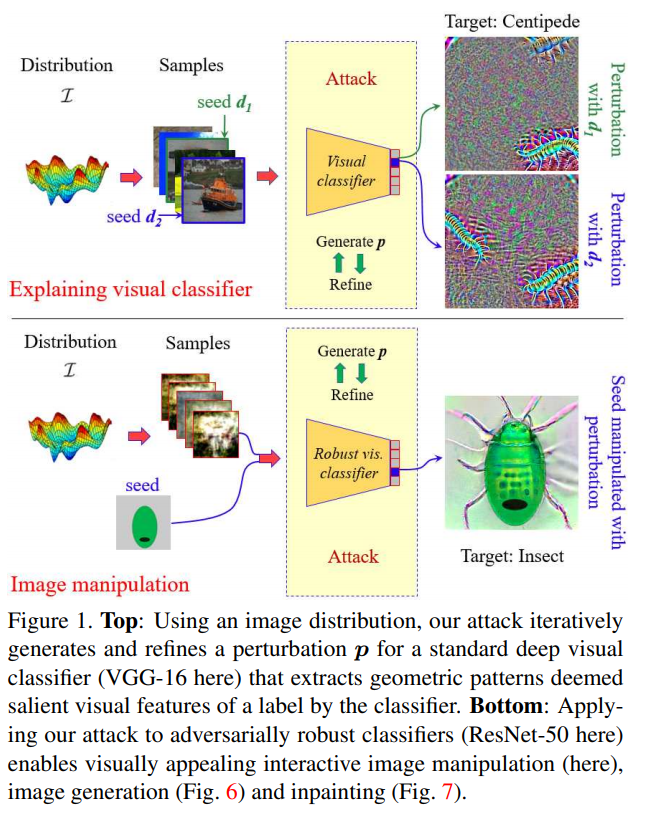
인간의 지각과 일치하지않은 representation이 여전히 인간 의미 visual task에서 높은 정확도를 가지는 것이 역설적이다. 그림 1 (top) 을 보면 적대적인 작은 변화가 포함된 상태로 분류를 하면 완전히 다른 라벨로 분류되며 salient visual feature에서도 확인할 수 있다. 하지만, salient visual feature들을 보면 사람이 사물을 인지하는 것과 deep model들이 인지하는 것에 큰 차이가 없어보인다. 오히려 원시적이고 감지하기 힘든 형태이기는 하지만, 적대적인 작은 변화를 대상 라벨의 인간 의미 가하학적 feature들로 볼 수 있다. -> 다시 해석하자면, 적대적인 작은 변화는 인간이 알아차리기 힘든 형태지만 라벨에 해당하는 feature을 가지게되는 것이라고 볼 수 있다. 이것으로 미루어보아 deep model들도 인간이 사물에서 특징들을 인식하는 것처럼 작동하는 것으로 볼 수 있다.
본 논문의 변화 평가 알고리즘은 확률적으로 주어진 대상 라벨에 이미지 분산에 의해 변화된 샘플의 예측 확률을 극대화한다. 본 저자들은 변화 신호를 분류기의 깊은 층에 있는 매우 활동적인 뉴런들에 집중하기 위해서 연결한다. 그림 1에서 확인할 수 있다.
게다가, deep model들이 이미지에서 집중적으로 보는 visual feature들을 설명하고 인간의 지각과 deep representation의 일치를 위해서 자연스럽게 low-level task에 집중하게되었다. e.g 이미지 생성, 인페이팅 그리고 interactive image manipulation.
본 논문의 major contribution:
1) attack technique을 fooling이 아닌 설명을 위해 사용함
2) non-robust model들에 작은 변화를 줘서 나온 salient visual feature들로 미루어보아, 인간의 인지와 deep models의 인지에는 차이가 없을 것 같음을 보여줌
3) 이미지 생성, 인페이팅 그리고 interactive image manipulation에 실험을 진행함. 왜냐하면 자연스럽게 low-level을 탐구하게되어서
2. Related Work
[2] adversarial attack에 관한 논문.
Adversarial attcks: 초창기에는 Szegedy [45]에서 시작했으며, Goodfellow가 FSGM[16]을 시작으로 I-FGSM[25], MI-FGSM[[13][13]], D$I^2$-FGSM[[51][51]] 그리고 vr-IGSM[48]이 나왔다.
위의 논문들과 다른 여러 논문들은 사람한테는 noisy로 보이지만 완전하게 모델을 멍청하게 만드는 것에 집중했으며 많은 이미지를 오분류하게 만드는 noisy인 Universal Advesarial perturbation인 [29]도 나왔다. 따라서, 실질적으로 high-level에 사용하는 분류기에도 이러한 위협이 가깝게 다가오기 때문에 현재 활발하게 연구 되고있다.
Adversarial defenses: adversarial attack에 대항하여 model에 들어오는 변화를 감지하고 막는 기술이다. 하지만, 강력한 adversarial attack이면 이러한 defenses도 뚫을 수 있다.
Non-adversarial perspective: adversarial attack을 공격용도가 아닌 해석용도로 사용한 논문 들도 있다. [46][46]과 [47][47]이 대표적인데, adversarially robust models들을 바보로 만드는 작은변화 신호를 salient visual feature의 존재를 관측했다. 이러한 것을 통해 model을 설명하는 것이다. 그러나, 몇몇 논문에서는 deep representation과 인간 지각이 일치 하지 않음을 주장한다. [14][[46][46]]
???? 번역기 돌린거... 이해가 안됨: 잠재적으로 재정렬은 오직 심각한 성능 손실과 컴퓨팅 복장성의 증폭으로 모델을 적대적으로 강건하게해야만 달성 할 수 있다.[14] [[46][46]].
3. Attacking to explain
Adversarial attack에서는 Deep visual classification model을 통과할 때, 잘못된 label로 구별하는 것을 목표로 한다. 식으로 나타내면,
$$
\kappa(\iota+p) \rightarrow \mathcal{l}_ {target} \ s.t. \ \mathcal{l}_ {target} \neq \mathcal{l}_ {true},||p||_p \leq \eta,
$$
$\kappa$는 Deep visual classification model, $p$는 perturbation, $||p||_p$는 norm을 뜻하며, $\eta$에 의해 제한된다.
위의 (1)를 보면, $\kappa$와 $I$로 $p$를 표현할 수 있으며, $\kappa$가 고정된다면, 이미지의 특정한 변화를 계산하기 위해 $p$의 도메인을 국한한다. 하지만,이런 제한은 단 하나의 데이터에 대한 특질만 반영하여 전체적인 분류기의 성질을 나타내기 어렵다. 또한, 이미지의 특정한 변화를 통한 인간의 지각과 deep representation 사이의 어긋남에 대한 의문을 제기할 수 있다. 작은변화와 함께 분류기의 특성을 더 잘 보여주기 위해서는 신호에 대해 변하지않는 입력 샘플이 필요하며, p의 영역을 확장하여 달성할 수 있다.
universal perturbations [29]와 같은 논문은 본 논문과 비슷한 내용을 담고 있는데, 많은 이미지에 대해서 처리할 수 있지만, salient feature map을 보면 기하학적인 모양은 매우 틀리다. 아마도, 특정한 물체가 아닌 무작위 class로 할당되도록 만들어서 그렇다. 주어진 Deep model ($\kappa$)에 'targeted' 목적으로 pertubation 영역을 넓히는 것은 Deep model $\kappa$에 의해 실제로 target의 특징이 두드러지게 p의 기하학적 패턴을 유도할 가능성이 있다.
--> 즉... p가 target의 기하하적 특징을 가지도록 유도할 수 있다.
(1)의 식에서 $l_{target}$을 매핑하는 $\kappa$의 확률을 최대하 하는 것으로 바꿀 수 있다. 즉, 모든 샘플들을 포함해서 최대화해야한다.
$$
\mathbb{E}[P(\kappa(I + p) \rightarrow l_{target})] \geq \gamma, \ s.t \quad
Dom(p) = {\forall I|I \backsim \mathcal{I}}, |Dom(p)| \gg 1, ||p||_p \leq \eta,
$$
$\gamma \in [0,1]$을 만족하며, (2)를 만족하는 $p$에는 위의 예시에 대한 명백한 정보가 드러내질 것으로 예상된다. (Dom은 정의역을 나타낸다.)
다음과 같은 질문이 생길 것이다.
1) 모델로 물체의 구별할 수 있는 시각 특징으로 여겨지는 게 무엇인가?
2) 모델의 주어진 label index는 의미론적으로 어떻게 볼 수 있는가?
3) feature들과 semanitcs가 인간 해석적이라고 볼 수 있을까?
4. Algorithm
2가지 단계로 나눠진다.
1) perturbation estimation: 전체론적으로 작은 변화가 목표 클래스의 구별가능한 feature들로 유도되도록 하는 것.
2) perturbation refinement: 이미지 구역들에서 작은변화가 더 많은 뉴런 활동을 할 수 있도록 하는 것
Perturbation estimation: perturbation 영역의 확장을 위해 입력의 분산이 필요하다. 입력 $I$는 다음과 같은 공식으로 결정된다. $\mathfrak{F} = {d} \cup \bar{D}$. $d$는 seed 이미지인 반면에 D는 입력으로 부터 온다. Perturbation estimation은 Algorithm.1 에서 확인할 수 있다. SGD를 사용한다.
$$
max_p \mathfrak{H}=\mathbb{E}_ {I \sim \mathfrak{F}} [P(\kappa(I + p)) \rightarrow l_{target}] \quad s.t. \ ||p||_2\leq \eta.
$$
핵심적으로, 알고리즘은 위의 공식인 (3)을 해결하기위해 시각적 모델의 cost surface 의 다단계 순회를 위한 분산 샘플의 mini-batch를 사용한다. 밑의 algortihm 1은 gradient monet와 mini-batch의 surface를 미분을 해 $\mathfrak{F}$을 최대화한다. 즉, SGD와 Momentum을 통해서 위의 (3)식을 최대화 한다. $\mathfrak{F} \geq \gamma$가 되도록 한다.

알고리즘을 설명하면
line 2: mini-batch인 b에서 -1을 한 b-1만큼 데이터 샘플을 뽑고
line 3-4: seed d와 최근의 perturbation을 샘플에 둘러싼다. 이 cliping은 0에서 1사이로 샘플을 국한시킨다. $\ominus$는 샘플이나 set에서 각각의 요소에 perturbation을 적용시키는 것을 뜻한다. 반복문 안에서는 SGD로 작동한다.
seed는 입력을 변경하여 perturbation의 변화를 허용하기 위해 알고리즘에 사용된다. 입력 샘플에 대한 제한을 정하지 않으며, D와 d가 매우 다를 수 있음을 나타낸다. 또한, $l_{traget}$에 직접적으로 gradient를 구한 것이 $d$에 계산된 것과 현저하게 다를 수 있음을 나타낸다. (denoted $\triangledown_{d_i} \mathcal{J}(d_i, l_{targe}))$
line 6: 이 차이를 설명하기위해, $d_i$에 대한 gradient norm을 $d_i \in D$의 평균으로 나눈 비율을 구한다.
line 7: 6에서 구한 비율을 여기서 결합하는데, seed gradient과의 높은 관련성을 얻기위해서 사용된다.
line 8-9: 위의 합성된 gradient로 first and second raw moment를 추산하는데 $\alpha$와 $\beta$로 조절한다. 위의 moment는 Adam algorithm으로 부터 영감을 받았다. 경험적으로 hyperparameter들의 영향이 비슷하며 Adam의 값으로 고정한다. -> 이것은 line 1에서 확인할 수 있다. 다른 값들은 0으로 초기화하는데 $\alpha$ 와 $\beta$만 특정한 값을 가진다.
line 10: 이동평균법을 적용 시킨 것
line 11-19: 중간의 perturbation을 업데이트 하는 신호 $\rho$ 결과를 찾도록 binary search를 실행 하는 부분. 그 이유는 확률적으로 본 논문의 알고리즘은 궁극적인 목표를 벗어날 수 있는데, 이러한 binary search가 억제한다고 한다. 즉.. 이 부분이 모델을 더 잘 설명할 수 있도록 한다.
line 20: $\eta$ 반지름의 $l_2-ball$를 updated perturbation에 투영한다.
line 21-22: 작은 변동과 clip을 거친 분산 샘플에 대한 $\mathfrak{H}$을 추산한다.
perturbation의 $l_p-norm$은 인식이 불가능하게 만드는 적대적 설정으로 제한되는 반면에, 본 논문에서는 전혀 다른 역할을 한다. 반복적인 back-propjection과 clipping을 통해, 모든 입력 샘플에 대한 $l_{label}$을 예측하는 $\kappa(.)$에 큰 영향을 미치는 기하학적인 패턴 perturbation을 증폭시킨다. 밑의 figure 2에서 확인 할 수 있다. 그리고 정제를 통해 더욱 더 잘 확인할 수 있다.

*Perturbation refinement: * 질 좋은 패턴을 뽑아내기위해 Algorithm 2를 보면 적절한 구역에서 적응할 수 있는 filter에 집중한 기술을 볼 수 있다.

이 알고리즘의 핵심은 앞선 외부의 영향이 없다는 가정하에 perturbation의 정확도를 유지하는 것이다.
line 2: perturbation을 정제하기위해서 분류기의 convolutional base인 $\bar{\kappa}(.)$을 입력으로 넣는다.
line 3: 출력인 $\Omega$는 낮은 해상도의 2D signal을 가지며, 평균 signal $a$에 의해 축소된 것이다. 이 signal은 입력 perturbation에서 대략적인 salient region의 윤각을 보여주어, 본 기술에 유용한 spatial filter가 된다.
line 4: $\Phi(.)$는 평균 signal에 대한 'Otsu threshold'를 계산한다.
line 5: 이미지를 이분화하기위해 위의 $\Phi(.)$를 사용한다.
line 6: 입력 perturbation의 차원을 맞추기 위해 결과로 나온 이미지에 bicubic interpolation로 upsampling 한다. 그 뒤에 scailed mask가 perturbation에 적용되고 뒤의 valid dtnamic range에서 cliping 한다.
알고리즘 2의 출력은 알고리즘 1에의해추가로 처리되며, 필터링으로 감소 할 수있는 sailent pattern을 다시 강조한다. 최종의 perturbatin은 위의 두가지 알고리즘이 반복적으로 실행되어 계산된다.
5. Experimentation
5.1 Model explanation
Setup: $I$는 original image이고 $\bar{D}$는 ILSVRC 2012 validation dataset에서 256개의 이미지를 랜덤으로 샘플링한 dataset이다. mini-batch인 $b = 32$, probability threshold인 $\gamma = 0.8$ and perturbation norm인 $\eta = 10$ 이다. $\gamma$는 최종 perturbation에서 salient pattern이 확연하게 보이는 값으로 정했다. 높은 $\gamma$는 더 깨끗한 패턴을 보이지만 더 높은 계산량을 가진다. $\eta$의 경우 기존의 논문끼리 비교를 통해 정했다. 하드웨어는 Titan V gpu with 12 GB RAM을 사용함.
perturbation을 구하기위해, Algorithm 1을 먼저 실행한다. (desired $\mathfrak{H}$) 그 후에 refinement를 위해 algorithm 2 를 실행한다. 그 후에, algorithm 1을 실행하지만 300 iteration 전까지 매 50 interation 마다 refinement (algorithm2) 를 실행한다.
Salient visual features: 본 논문에서는의 공격은 이러한 perturbation의 signal을 통해 target label들의 salient feature들을 발견할 수 있도록 한다. 그림 3을 보면 확연하게 볼 수 있으며, 어떤 perturbation이 없더라도 패턴이 나타남을 알 수 있다.

위의 그림을 보면서 먼저 '사람-이해 의미론적인 것이 출력 뉴런에 연결 되는 것'에 대한 답을 내릴 수 있다. 즉, 잘 모르는 모델을 가지고 label의 output layer을 봐야할 때 유용하다. 두번째로, "분류기로 부터 해당 클래스를 구분하는 특징이 어떤 기하학적 패턴을 가지는가?''에 대한 답을 내릴 수 있다. 그림을 보면 사람 개념과 유사하게 패턴을 잘 정렬한다. 즉.. 딥러닝이 사물을 인식하는 것과 사람이 사물을 인식하는 것과 유사하다고 볼 수 있다.
Diversity of the salient patterns: 그림 3에서 다른 모양으로 나타나는 이유는 seed를 다르게줘서 그렇다. 그리고 salient map을 통해서 deep learning model 또한 사람이 사물을 인식하는 것처럼 인식한다고 단언할 수 있다. $\bar{D}$는 독립적으로 생성해서 실험을 진행 하였는데, 이러한 패턴들이 visual model을 통해 만들어지고 보여진다. (image generation and image classification)
Region specific semantic: 이미지 공간의 특정 영역과 관련된 모델 의미론을 추출 할 가능성에 대해서도 탐구했다. 이렇게하면 개별적인 샘플의 기울기가 지정된 영역에 대해 동일한 방향으로 이끈다. back-projection으로 해당 영역의 신호를 강화하는 반면 다른 영역의 약한 신호는 정제를 통해 억제된다. 모든 샘플에 대해 관심 이미지 영역을 64x64 패치로 대체하여 모방하는데, 모든 패치 픽셀은 샘플의 평균 픽셀 값으로 생성된다.

그림 4는 지네를 라벨로 랜덤한 영역에 넣어서 salient feature map을 보인 결과이다. 보는 것과 같이 공격은 특정 영역근처에 더 집중적이다. 흥미롭게도, 대상 라벨의 유사한 차별적인 특징을 일관된 방식으로 서로 다른 영역에 연관시킬 수 있으며, deep representation과 인산 인식 사이의 차이점이 없어 보인다.
*Patterns for different models: * 위의 그림 4는 resizing을 한 뒤에 보여준 패턴이다. 그러나, salient visual feature들의 나타남은 deep visual classifier에서 나타나는 일반적인 현상이다.

그림 5에서 보듯이 perturbation들은 모든 모델에서 해당 라벨의 특징을 명백하게 묘사한다.
해당 모델에 대해서 여러 모델들의 높은 confidence는 추출된 패턴들이 해당 class의 구별가능한 visual feature들로 잘 보이는 것으로 나타낸다. -> 즉... 어떤 모델에서든 추출한 visual feature들은 다른 모델에서도 잘 작동시킬 수 있는 visual feature들을 뽑아 낸다는 것이다.
5.2 Leverage in low-level tasks
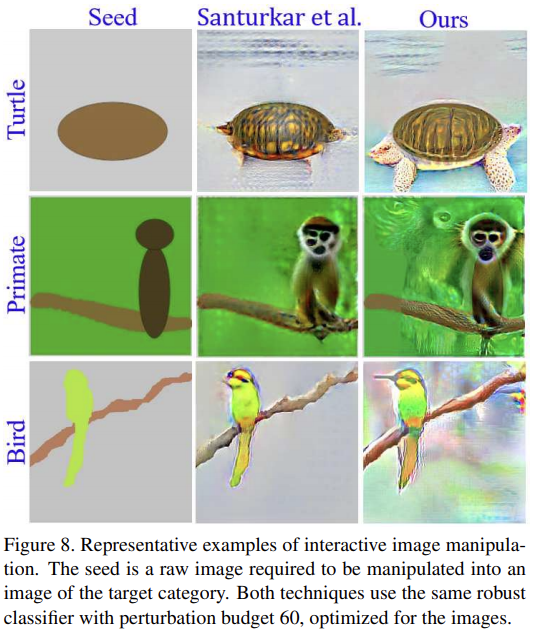
Santuraker et al 41은 이미지 생성과 인페이팅에서 자신들의 모델을 증명햇으며, 적대적인 robust deep calssifier들을 사용했다. 또한, 강력한 분류기를 위해 계산된 적대적 perturbation에서 salient visual feature의 존재에 대한 논문이다. 위의 논문도 우리의 발견과 관계가 있다. 성공적으로 모델을 설명할 수 있을 뿐만 아니라 SOTA를 달성했다.
결과에 대한 개선점을 증명하기위해 41과 똑같은 budget과 평가 과정을 사용하였다. $\bar{D}$를 샘플링 할때는 다중 가우시안 분포 $N(\mu_1,\Sigma_1)$를 사용했으며, ImageNet에서 가져왔다. 계산을 위해 다중 가우시안 분포는 원본의 이미지들의 4x downsampling을 사용하였다. 랜덤으로 256개 분포 샘플들은 네트워크 입력과의 일치를 위해 나중에 업샘플링되고 $\bar{D}$에 사용된다. 전체적으로 이미지 프로세싱은 했지만, refinement step을 제외하였다.
5.2.1 Image Genearation

적대적 공격의 맥략에서, 생성된 이미지는 seed image의 적대적인 예시이다. 다양한 시드, 텍스쳐 세부 정보 및 명확한 의미 일관성으로 생성된 이미지의 다양성은 강력한 분류기가 분류 이상을 수행 할 수 있음을 의미한다.
5.2.2 Inpainting
다음의 task를 해결하기 위해 변질된 이미지를 binary mask로 알아보게 만든 seed로 다룬다. robust classifier parameter들을 고정하고 밑의 loss를 최소화 하는 것으로 목표로 한다.
$$
L(p)=\mathbb{E}[\mathcal{J}(\mathfrak{F}_ p,l_{target})+\beta(p\odot(1-F))],
$$
$\mathfrak{F}_p = \mathfrak{F}\ominus p,$ $\mathcal{J}$는 cross-entropy loss 이다. $\beta=10$으로 고정하며 실험적으로 얻어낸 scaling factor이다. 위의 loss function은 perturbation 신호가 제한 없이 변질된 이미지를 다른 구역과는 자유롭게 해결하기위해 만든다.

41과 비교한 그림이며 같은 perturbation budget 인 $\eta=21$를 사용했다. 시각적으로도 잘 생성하고 더 좋은 결과를 가져온다.
5.2.3 Interactive Image Manipulation
대충 그린 스케치로 부터 그림을 생성하는 기술을 attacking/fooling robust classifiers로 해결할 수 있는 가능성을 41에서 제시했다. 논문의 기술이 더 적합함을 보였다.
다중 가우시안 분포를 사용하여 만들었지만 refinement 과정이 포함되어있다. 결과는 밑의 그림에서 확인 할 수 있다.
위의 3가지 기술 (generation, inpainting and manipulation)을 통해 perturbations이 보통적으로 모델을 바보로 만들 뿐만 아니라 저자들이 알고자하는 방향에 대한 확신을 준다고 한다.
6. Conclusion
본 논문은 모델을 바보처럼 만드는 것이 아닌 설명을 목적으로 한 attack의 첫 논문입니다. 작은 변화를 계산하기위해 공격은 모델의 cost surface에 대해 stochastic gradient search를 수행하여 특정 대상으로 분류 될 이미지의 '분포' 로그 확률을 높인다...(?) 반복적으로 기울기의 back-projection 와 adaptive attention와 함께 재정의 함으로써, 논문의 공격은 분류기의 salient로 여겨지는 작은 변화인 기하학적인 패턴을 발견했다. 현실적인 이미지생성, 인페이팅 그리고 interactive image manipulation은 모델에 대한 공격의 nature을 알아냈으며, 사전의 SOTA에 대한 새로운 분류기 활용을 발견했다.