EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Mingxing Tan Quoc V.Le
Abstract
ConvNet들은 공통적으로 고정된 자원안에서 계발되고 그 후에 더 좋은 정확도를 위해 이용가능한 자원을 사용한다. 본 논문에서는 네트워크의 깊이, 너비, 그리고 해상도를 적당히 조절하여 더 좋은 성능을 가져옴을 연구했다. 해당 요소를 'compound coefficient'라고 한다.
또한, neural architecture search 기술을 이용해 EfficientNet이라는 베이스라인을 사용했으며, 8.4배 더 작고 6.1배 더 빠른 내트워크를 만들었다. 물론, SOTA도 기록했다.
1. Introduction
Scaling을 통해 정확도를 올리는 것은 옛날부터 이어져왔다. ResNet이나 GPIpe 같은 모델들이 있다. 현재 scaling 방법에는 총 3가지 정도가 유행하는데, depth (ResNet [1][1]) , width (Wide ResNet [2][2]) 그리고 resolution (Gpipe [3][3]) 이 있다. 위의 3가지 차원을 임의로 scaling 하는 것은 지루한 tuning이 되고 그것 또한 sub-optimal accuracy와 efficiency 일 것이다.
논문에서는, ConvNet scaling 과정에 대해서 다시 생각해보고 연구했다. 주요 물음은 "더 좋은 정확도와 효율성을 달성하기 위해 ConvNet을 scaling하는 원칙에 입각한 방법이 있을까?" 이다. 고정된 비율로 각 요소에 대해 scaling을 하면 적절한 balance를 가질 수 있다. 이러한 방법을 Compound Scaling Method라고 한다. 이 방법은 공평하게 네트워크의 너비, 깊이 그리고 해상도를 scaling 하는 것이다. 예를 들어 제한된 자원이 $2^N$이라면, 깊이는 $\alpha^N$, 너비는 $\beta^N$ 그리고 해상도는 $\gamma^N$이다. 상수의 계수는 original model에서 grid search를 통해서 결정된다. 밑의 그림에서 확인 할 수 있다.
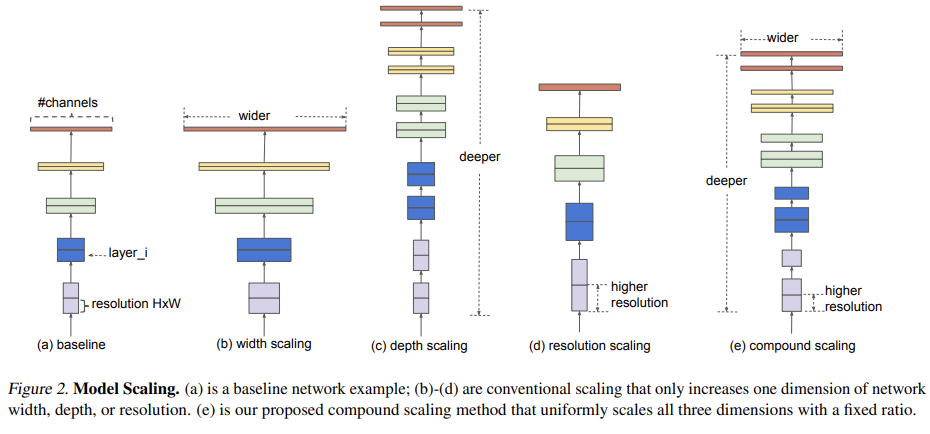
직갑적으로, 복합체 scaling 방법은 의미가 있다. 본 논문은 width, depth 그리고 resolution 세가지 사이의 관계에 대해 수량화한 첫번째 논문이다.

특히, 모델 scaling의 유효성은 베이스라인 네트워크에 의존 적인데, NAS를 사용해 EfficientNet을 베이스라인으로 사용했다. 그림 1을 보면 현저한 차이를 볼 수 있다. 이 때 당시의 최고 성능인 GPipe [3][3] 보다 8.4배 작은 파라미터를 가지며, 6.1배 더 빠르다. 또한,** EfficientNet들은 ImageNet에서 학습한 후 transfer learning을 통해 다른 데이터 셋에서도 좋은 성능을 보임을 보였다.**
2. Related Work
ConvNet Accuracy: AlexNet을 시작으로 ConvNet들은 정확도를 올리기 위해 더욱 더 커져갔다. 최근에는 GPipe 라는 제일 좋은 성능을 가지는 네트워크가 나왔는데, 특별한 pipeline parallelism library를 사용해 네트워크를 나누고 다른 accelerator를 각 부분에 분배하는 방식을 사용한다. 또한, ImageNet에서 성능이 좋으면 다른 데이터 셋으로 transfer learning에서 좋은 성능을 보였다. 하지만, 더 높은 정확도가 중요하지만, 하드웨어 메모리에 제한은 있으므로, 더 좋은 효율성을 얻는 것이 중요해졌다.
ConvNet Efficiency: Deep ConvNet들은 너무 과도한 파라미터들을 가진다. 따라서 모델 압축 기술이 나왔는데 [4][4], [5][5], 그리고 [6][6] 등이 있다. 또한, 직접 모델을 구축한 ,SqueezeNet, MobileNet 그리고 ShuffleNet 등이 있다. 최근에는 NAS가 등장해 효과적인 모바일 크기의 ConvNet ( [7][7] [8][8] )등이 등장 했으며 사람이 디자인한 ConvNet들 보다 더 좋은 성능을 보인다. 본 논문에서는 SOTA에 대한 모델 효율성에 집중한다. 그 후에 scaling에 따라 재분류한다.
Model Scaling: ResNet ([1][1]) 과 같은 모델은 네트워크의 깊이에 대해 신경을 썼으며, Wide ResNet ([2][2])과 MobileNet ([9][9])은 네트워크의 너비에 대해 신경을 썼다. 또한, 입력 해상도가 클 수록 좋은 성능을 보이는 것은 잘 알려진 사실이다. 과ㅏ거의 논문들은 깊이와 너비가 다 중요하다고 하지만 여전히 효율성과 정확도를 더 좋게하는 것에 대한 연구는 지속적으로 진행중이다. 본 논문에서는 ConvNet에 대한 너비, 깊이 그리고 해상도의 모든 차원 scaling에 대한 연구이다.
3. Compound Model Scaling
본 섹션에서는 scaling 문제를 공식화 하고 다른 접근법에 대해 소개하고 논문에서 만든 새로운 scaling method를 소개한다.
3.1 Problem Formulation
ConvNet Layer를 $i$라고 할 때, $Y_i=F_i(X_i)$ 이라고 할 수 있다.
$F_i$는 operator, $Y_i$는 출력, $X_i$는 입력 그리고 tensor 모양은 $<H_i, W_i, C_i>$ 이다. 따라서, ConvNet을 다음과 같이 나타낼 수 있다: $N=F_k \odot...\odot F_2 \odot F_1(X_1)=F_k \odot_{j=1...k}F_j(X_1)$
보통 Deep convNet의 경우 각 stage와 같은 구조를 가진다. ResNet의 경우 5개의 stage로 나눠져잇으며, 다운 샘플링을 하는 부분을 제외하고 같은 convolutional type을 가진다. 따라서 밑의 수식과 같이 ConvNet을 표현할 수 있다.
$$
N=\odot_{i=1...s}F_i^{L_i}(X_{<H_i,W_i,C_i>})
$$
i stage에서 $F_i$ layer가 $L_i$번 반복 되는 것을 뜻한다. fig2 (a)는 전형적인 ConvNet을 보여주며, 점점 spatial dimension이 작아지지만, Channel의 수는 증가한다.
일반적인 ConvNet을 디자인 하는 것과 다르게, 본 논문은 네트워크 layer의 구조가 아닌, lenghth, width 그리고 resolution을 변경한다. 물론, 고정적인 상수를 두고 비율을 변화시키는 방법을 사용하였다. 이것을 공식화하면:
$$
\max_{d,w,r} Accuracy(N(d,w,r)) \\
s.t. \quad N(d,w,r)=\odot_{i=1..s} \hat{F}i^{d \cdot \hat{L_i}} (X{<r\cdot \hat{H}_i, r\cdot \hat{W}_i,r\cdot \hat{C}_i}) \\
Memory(N)\leq target_memory \\
FLOPS(N)\leq target_flops
$$
w,d,r 은 각각 width, depth 그리고 resolution을 뜻하며 $\hat{A}$이 들어간 것은 이미 정의된 베이스라인 네트워크를 뜻한다.
3.2 Scaling dimensions
d, w, r은 서로서로 의존적이고 다른 resource constraints 아래에서 바꿔야함으로 scaling이 매우 어렵다. 각각은 다음과 같이 scaling 한다.
Depth (d): scaling network depth는 ConvNet의 정확도를 올리는 간편한 방법중 한가지이다. 하지만, 깊은 네트워크 일수록 gradient vanishing 문제를 해결하기가 어렵다. 하지만, Skip connection과 batch normalization이라는 방법이 나왓지만, 그래도 여전히 깊어질 수록 무조건 좋은 성능을 가져오는 것은 아니다.
Width (w): 더 넓은 너비를 가지는 네트워크는 쉽게 학습되고 fine-grained feature들을 잘 추출할 수 있다. 하지만, higher level feature들을 봅아 오는 걸 어려워하는 경향이 있다.
Resoultio (r): 더 큰 해상도는 더 많은 fine-grained pattern을 찾을 수 있다. 299x299 (Inception), 331x331 그리고 480x480 (GPipe)에 이르는 해상도를 가진 네트워크들도 있다. 하지만, 매우 높은 (560x560) 해상도에서는 도리어 정확도가 떨어지는 경향이 있다.
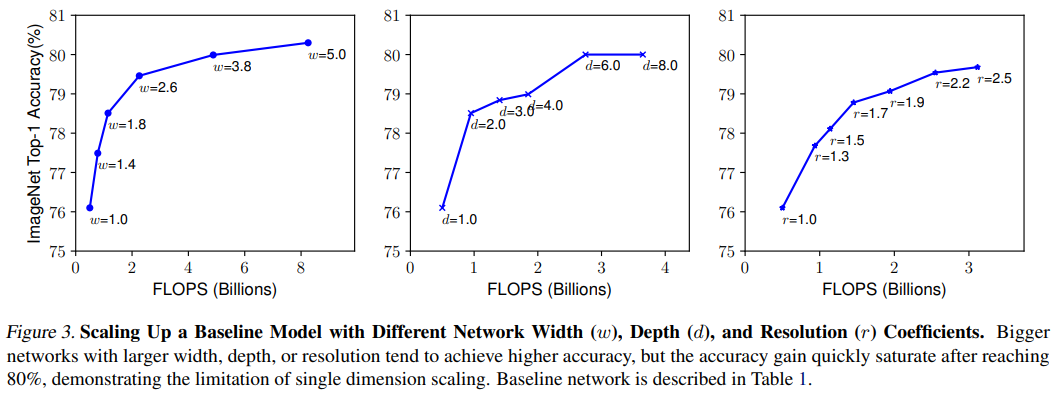
Observation 1: 너비, 깊이 그리고 해상도를 증가시키면 정확도가 상승하지만 도리어 매우 클 경우 정확도 상승이 없어진다. -> 즉, 적당한 크기가 존재한다는 것이다.
3.3 Compound Scaling
실험적으로, 다른 scaling dimensions들이 의존적이라는 것을 관찰했다. 직관적으로, 더 큰 해상도에서 더 깊은 네트워크나 넓은 네트워크의 정확도가 좋을 것이다. 따라서, 본 논문에서는 단일 dimension에 대해 실험을 진행한 것이 아니라, 여러 조합을 사용해 진행하였다.

위의 그래프를 살펴보면 깊이만 늘린 것보다 해상도와 함께 깊이를 올리는 것이 더 좋은 성능을 가져온다.
Observation 2: 더 좋은 정확도와 효율성을 추구하기 위해서는 너비, 깊이 그리고 해상도를 적절하게 scaling 해야한다.
본 논문에서는 새로운 compound scaling method를 제안하며 compound coefficient $\phi$로 표현한다.
$$
depth:\ d=\alpha^{\phi} \
width:\ w=\beta^{\phi} \
resolution:\ r=\gamma^{\phi} \
s.t \quad \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2 \
\alpha \geq1,\beta \geq1, \gamma \geq1
$$
$\alpha,\beta,\gamma$는 grid search를 통해서 결정된다. 일반적으로 FLOPS는 $d,\ w^2,\ r^2$의 배율로 증가한다. 본 논문에서 새로운 $\phi$로 제한을 햇으며, 전체적인 FLOPS는 대략적으로 $2^\phi$만큼 증가한다.
4. EfficientNet Architecture
model scaling은 베이스라인 네트워크를 바꾸는 것이 아니기 때문에, 새로운 mobile-size baseline 인 EfficientNet을 만들었다.
MNAS ([7][7])에서 영감을 얻어 같은 search space와 $ACC(m) \times [FLOPS(m)/T]^w$를 사용했다. $T$는 목표하는 FLOPS 이며 $w=-0.07$로 정확도와 FLOPS 사이를 제어하는 하이퍼 파라미터이다. MNAS랑은 다르게 지연속도보다는 FLOPS를 최적화 하는데 목표를 두었다. 따라서 EfficienNet-B0가 나왔으며, MNASNet과는 유사하지만, 조금 더 많은 FLOPS를 가진다. 밑의 표1에서 구조를 확인할 수 있다. mobile inveted bottleneck인 MBConv를 주요 block으로 두고 squeeze-and-excitation ([10][10]) 최적화도 추가했다.

밑의 2가지 단계를 거쳐 scaling 된다.
- STEP 1: $\phi=1$로 고정하고 grid search를 통해 $\alpha,\beta,\gamma$를 수식 2, 3에서 찾는다.
- STEP 2: $\alpha, \beta, \gamma$를 고정한뒤 다른 $\phi$를 적용하여 수식 3을 완성한다.
간략하게 요약하면, 작은 베이스라인 네트워크를 찾고 (STEP 1) 적절한 scaling coefficient들을 찾는다. (STEP 2)
5. Experiments
5.1 Scaling Up MobileNets and ResNets
당시에 대표적인 ConvNet들인 mobileNet과 ResNet에 대한 scaling method를 적용하고 비교했다. 밑의 표3에서 확인할 수 있다.

5.2 ImageNet Results for EfficientNet
첫 문단에서는 ImageNet을 학습하는 환경에 대한 설명들이다.
- RMSProp optimizer, decay: 0.9, momentum: 0.9
- BN 사용, momentum: 0.99
- weight decay: 1e-5
- Initial learning rate: 0.256, 매 2.4 epoch 마다 decay:0.97
- SiLU (Swish-1) 사용
- AutoAugment 사용
- 잔존확률: 0.8로 stochastic depth 사용
- dropout 사용, 0.2(B0) ~ 0.5(B7)
- trainingset에서 25K를 minival set으로 사용
- validation 도중 최종 validation accuracy 도달 시 early-stopping

위의 표를 보면 비슷한 정확도에서 좀 더 효율적인 구조를 가지는 것으로 확인할 수 있다.

그림1과 그림 5를 비교하면 EfficientNet이 더 작고 효율적이라는 것을 확인할 수 있다.

지연시간 평가를 했으며, 위의 표 4를 보면 확인 할 수 있다.
5.3 Transfer Learning Results for EfficientNet

위의 표6을 보면 transfer learning에 사용한 데이터셋에 대해서 볼 수 있다.

위의 표5를 보면 tranfer learning에 대한 결과를 볼 수 있다.
1) 유명한 모델들인 NASNet-A 와 Inception-v4 에 대한 결과를 비교 했다.
2) 당시 SOTA 인 Gpipe에 DAT를 적용한 것과 비교를 했다.
마지막으로 밑의 그림 6을 보면 각 데이터 셋에서 EfficientNet이 얼마나 효율적인지를 볼 수 있다.

6. Discussion
Efficient 모델과 scaling method에 대한 공헌을 구분하기위해 그림 8을 보면 확연하게 알 수 있다. 다른 scaling method와의 비교를 통해 본 논문에서 제안한 scaling method가 더 효율적인 것을 알 수 있다.

또한 그래프상이 아닌 activation map을 통한 비교를 그림 7에서 볼 수 있다. 확연하게 compound scaling method가 더 잘 나타내는 것을 알 수 있다.

7. Conclusion
깊이, 너비 그리고 해상도를 밸런스있게 하는 것도 중요하지만, 더 나은 정확성과 효율성을 방해한다는 사실을 발견했다. 본 논문에서는 더 적은 FLOPS와 더 좋은 성능을 가진 EfficientNet 모델을 발견했다.
[1]: https://arxiv.org/abs/1512.03385 ""ResNet""
[2]: https://arxiv.org/abs/1605.07146 "Wide ResNet"
[3]: https://arxiv.org/abs/1811.06965 ""GPipe""
[4]: https://arxiv.org/pdf/1510.00149.pdf "Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding"
[5]:https://arxiv.org/abs/1802.03494 "Amc: Automl for model compression and acceleration on mobile devices"
[6]:https://arxiv.org/abs/1804.03230 "Netadapt: Platform-aware neural network adaptation for mobile applications"
[7]:https://arxiv.org/abs/1807.11626 "MNASNet"
[8]:https://arxiv.org/abs/1812.00332 "ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware"
[9]: https://arxiv.org/abs/1704.04861 ""MobileNet""
[10]: https://arxiv.org/abs/1709.01507 ""SENet""