Dynamic Feature Learning for Partial Face Recognition
L. He H. Li Q. Zhang Z. sun
Abstract
Partial face Recognition (PFR)은 CCTV나 모바일 환경같은 자유로운 환경에서 매운 중요한 task이다. 본 논문은 Fully Convolutional Network (FCN)과 Dynamic Feature Matching (DFM)을 조합해 PFR문제를 해결한다. sliding loss롤 FCN을 최적화 하며 intra-variantion을 줄인다.
1. Introduction
full 또는 frontal images face recognition은 쉽게 해결할 수 있는 문제이다. 하지만 , PFR은 전통적인 face recognition approaches로는 해결하기 힘든 문제들이다. 그림1과 같이 모자, 마스트 또는 스카프를 착용하거나 사람이나 건물에 가려져서 인식하기 힘들다.

존재하는 face recognition algorithm들은 고정된 입력 사이즈를 사용한다. 하지만, MRCNN 10은 얼굴과 부분 얼굴로 구역을 나눠서 feature을 추출하고 인식에 사용했다. 하지만, 중복되는 구역을 보는 계산량의 문제가 있는데, 이것은 Sliding window Matching (SWM 43)을 사용하면 줄일 수 있다. 여전히 sliding window는 필연적으로 같은 구역을 반복적으로 탐색하기 때문에 효율이 좋다고 할 수는 없다.
Dynamic Feature Matching (DFM)으로 좋은 효율성과 모호한 크기의 얼굴 이미지를 다룰 수 있다. 밑의 그림 2는 DFM의 구조에 대한 것이다.
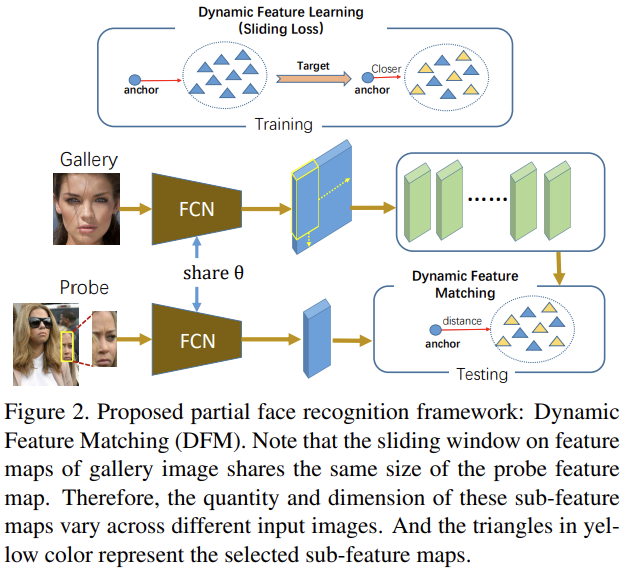
먼저, FCN으로 spatial feature map을 galley와 probe로 부터 뽑아낸다. 추출된 feature map은 VGGFace에 사용된다. 마지막 pooling layer은 입력된 face의 크기에 상관없이 똑같은 feature extractor가 사용된다. 그 다음에, gallery feature map은 sub-feature map으로 분해된다. 마지막으로 Sparse Representation Classification (SRC)에 의해서 probe feature map과 gallery sub-feature map과의 유사도를 구한다. DFM은 MR-CNN보다 20배는 빠르다고 하며, 논문에서 제안하는 sliding loss는 추출된 feature map과 anchor의 유사도를 계산할 수 있다고 한다.
Contribution:
- FCN과 SRC를 조합한 DFM
- 전체적인 얼굴 뿐만 아니라 부분적인 얼굴도 인식가능한 DFM
- 더 많은 deep feature를 학습할 수 있는 sliding loss
2. Related Work
2.1 Deep Neural Networks.
CNN은 image classification, object detection 그리고 semantic segmentation을 해결할 수 있다. DeepFace 35 를 시작으로 VGGFace 26, Light CNN 39, FaceNet 32 그리고 SphereFace 16이 차례대로 등장했다. 게다가 최근에는 Spatial pyramid pooling (SPP) 8이 등장했는데, 모호한 크기의 인풋을 고정된 길이의 representation을 FCN에 제공할 수 있다.
2.2 Sparse Representation classification.
얼굴인식에 SRC를 사용한 유명한 논문은 38이며, 42, 40 등도 있다.
2.3 Partial Face Recognition.
Hu 11은 alignment 없이 SIFT descriptor representation이 가능한 방법을 제안했으며 instance-to-class (I2C)를 계산하였다. Liao 15는 alignment-free 접근 법인 multiple keypoints descriptor SRC (MKD-SRC)를 제안하였다. 본 방법은 keypoint들 사이에 변하지않는 것이 있으므로 그것을 특징으로 구별한다. Weng 37은 Robust Point Set Matching (RPSM) 방법을 사용해 SURF descriptor 그리고 LBP histogram을 적용하였다. region-based model들도 해결법으로 적용할 수 있다. 눈, 코, 얼굴의 반 그리고 눈 주위에 대한 정보를 사용하였다. 제일 최근에는 He 10 Multi-Scale Region-based CNNs (MRCNN)이 있다. 하지만 얼굴 구성과 pre-alignment가 필요하다. 따라서, 본 논문에선는 alignment-free PFR 알고리즘인 DFM을 소개하며 높은 정확도와 높은 효율성을 보인다.
3. Out Approach
3.1 Fully Convolutional Network
convolutional layer은 sliding-window 방법과 spatial 출력들을 만들어낸다. fully-connected layer는 고정된 차원 특징과 공간 좌표를 없애버린다. 따라서, 고정된 길이를 가져오는 fully-connected layer은 필요가 없다.
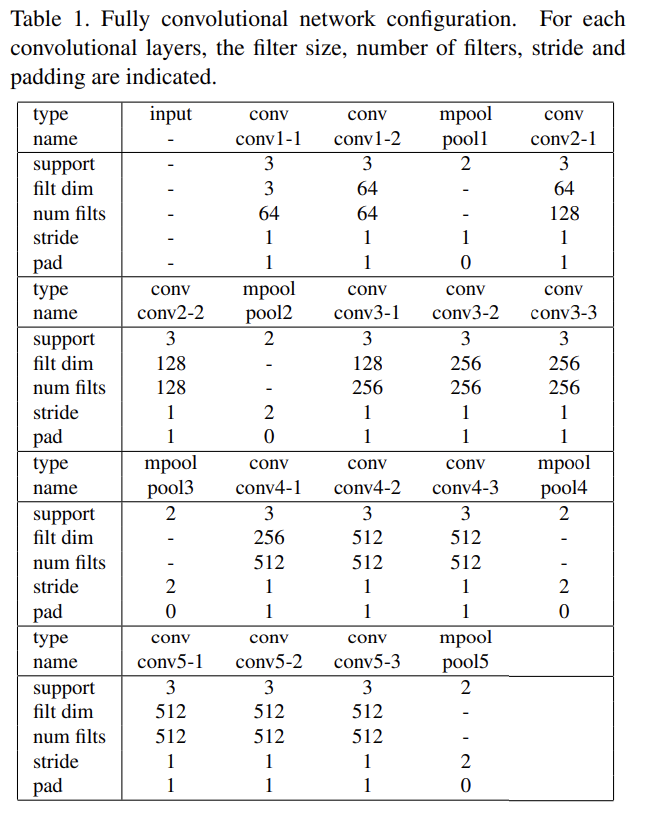
밑의 표1을 보면 VGGFace의 구조인데, fully-connected layer가 없다. 그 이유는 다양한 입력 사이즈에 대한 출력이 필요하며 더 견고한 feature를 뽑는데 필요가 없기 때문이다. 이처럼 모든 convolutional layer로 이루어진 구조를 Fully-convolutional network (FCN) 이라고 명명한다. FCN은 입력 크기의 제한 없이 서로 맞는 크기의 spatial feature map들을 뽑아낼 수 있다.
3.2 Dynamic Feature Matching
해당 섹션에서는 DFM에 대한 설명을 하는데, prob와 gallery에 대한 설명부터 한다.
prob: FCN에 의해서 feature map인 $p$가 나온다. 해당 $p$는 각각 너비, 높이 그리고 채널에 해당하는 $w,h,d$를 가진다.
Gallery: spatial feature map인 $g_c$는 FCN에 의해서 gallery의 $c$에서 feature 가 추출되어 나온다.
명백하게, prob와 Gallery의 차원이 불일치하면 계산을 할 수가 없다. 따라서, Gallery의 feature map인 $g_c$에서 prob의 feature map인 $p$ 만큼 sliding window로 잘라낸다. 위의 그림 2에서 보이는 것처럼 k개의 sub-feature maps은 $G_c = [g_{c_1},g_{c_2},...,g_{c_k}]$로 나타낼 수 있다. $G_c$는 probe 크기에 따라 $G_c \in \mathbb{R}^{M\times k}$이다.
정렬없이 feature matching을 위해서 $p$가 $G_c$의 선형 결합으로 표현되는 error reconstruction으로 문제를 바꿀 수 있다. 따라서, $G_c$에 관한 p의 계수를 계산할 것이다. 그리고 그 계수를 $w_c$로 표현한다. reconstruction error를 matching score로 표현할 수 있으며 최종적으로 $w_c$를 풀기위해서는 reconstruction error를 최소화 해야한다.
$$
\mathcal{L}(w_c)=||p-G_cw_c||_2^2
$$
$w_c\in \mathbb{R}^{k+1}$과 $p \in \mathbb{R}^{M+1}$이다. $w_c$를 구하기 위해 2가지 제한조건이 있는데 sparsity와 similarity 이다.
Sparse constraint는 feature vector $p$로 부터 나온 coding vector $w_c$의 sparsity를 컨트롤한다. 따라서, $w_c$는 $l_1-norm:\ ||w_c|| _1$을 사용한다.
Similarity-guided constraint.
feature $p$를 재구성한 sub-feature를 자유롭게 사용하는 재구성 프로세스에는 단점이 있다. $G_c$의 선형 조합을 위해 재구성 에러를 최소화하기 위해서 재구성 프로세스에만 집중하기 때문에 $p$와 feature vector $G_c$의 유사도를 고려하지 않는다. 즉, 재구성 에러를 최소화에 집중하기 때문에 비슷하지않은 feture vector들이 선택될 수 있다.
$p$와 $G_c$의 유사도를 계산하기위해 $l_2-norm$으로 1에 가깝게 정규화를 한다. 그러면 유사도 점수 벡터인 $p^TG_c \in \mathbb{R}^{1\times k}$는 cosine similarity measure이 된다. 이렇게 되면 유사ㅣ하면 더 많은 $g_c$가 선택되고 아니라면 제외된다. 즉, $p^TG_c$는 연관성을 보여준다. 그 후, similarity-guided constraint인 $p^TG_c W_c$가 정의된다.
최종 sparse representation formulation은 다음과 같다.
$$
L(w_c)=||p-G_cw_c||_2^2-\alpha^TG_cw_c+\beta||w_c||_1
$$
$\alpha$ 와 $\beta$는 각각 similarity-guided constraint 와 sparsity constraint을 나타낸다.
그 후에, $w_c$를 최적화 하기위해서 다음과 같이 변형한다.
$$
L(w_c)=\frac{1}{2}w_c^TG_c^Tw_c-(1+\frac{\alpha}{2})p^TG_cW_c+\frac{\beta}{2}||w_c||_1.
$$
$w_c$를 구하기 위해서 feature-sign search algorithm [14][14]를 사용하는데, $w_c$에서 Non-zero 값은 선택된 sub-feature vectors이다.
그리고 dynamic matching method를 적용해 probe와의 유사도를 검증한다.
$$
\underset{c}{min}\ r_c(p)=||p-G_cw_c||_2-\alpha^TG_cw_c.
$$
위의 수식은 reconstruction error와 weighted matching scores을 퓨전 합 한 것이다.
새로운 probe를 증명해야할 때, gallery feature map들을 다른 크기의 probe 이미지에 따라서 재분해한다. 따라서, gallery를 동적으로 사용할 수 있다. 또한, FCN의 몇며 layer들은 매우 효과적으로 output feature map 크기를 줄이기 때문에 효율성도 좋다.
논문에서는 probe의 크기가 $5\times5$이라면, $g_c$의 크기는 $7\times 7$이 되고, stride는 1 그리고 decomposition operation 인 $k=9$로 설정하면 된다고 한다.
DFM은 빠르게 feature를 뽑아낼 수 있으며, alignment-free method이며 다양한 크기의 probe로 부터 face recognition이 가능하다고 한다.
3.3 Sliding Loss
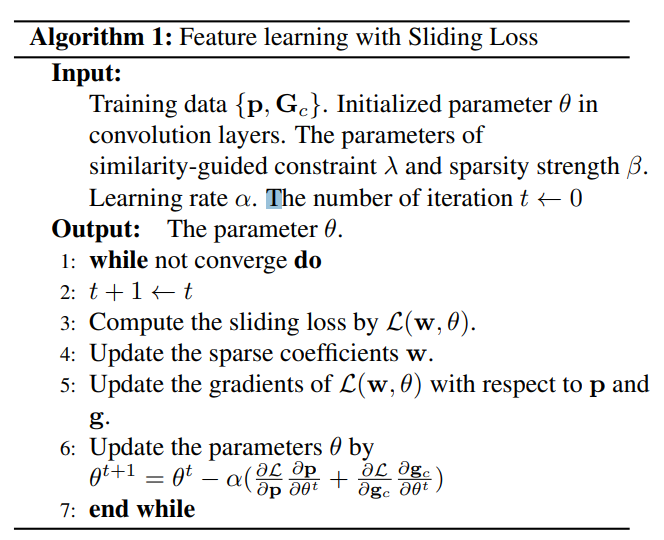
식 2에서는 FCN의 파라미터들은 고정되어있다. 따라서, 계수 $w_c$와 convolution parameters 인 $\theta$를 학습하기위해 Sliding Loss를 사용한다. 해당 Loss는 식 2를 최소화함으로써 나오는 deep feature들의 구분성을 계선하는데 사용한다.
$$
L(w_c,\theta)=y_c(||p-G_cw_c||^2_2-\alpha p^TG_cw_c)+\beta||w_c||_1.
$$
여기서 $y_c$가 1이면 $p$와 $G_c$는 같은 identity를 가지고 있는 것이며, $||p-GW||_2^2-\alpha p^TG_cw_c$를 최소화 하는 것이다. $y_c$가 -1이면 $p$와 $G_c$는 다른 identity를 가지고 있는 것이며, $-||p-GW||_2^2-\alpha p^TG_cw_c$를 최소화 하는 것이다.
3.4 Optimization.
처음에 $w_c$을 최적화하고 그 뒤에 $\theta$를 최적화 한다.
Step 1: fix $\theta$, optimize $w_c$.
reconstruction coefficients인 $w_c$를 feature-sign search algorithm을 사용해 학습시키는 것이다.
식 5를 변경한 것이다.
$$
L(w_c)=\frac{1}{2}y_cw_c^TG_c^TG_cw_c-y_c(1+\frac{\alpha}{2})p^TG_cw_c+\frac{\beta}{2}||w_c||_1,
$$
Step 2: fix $w_c$, optimize $\theta$.
FCN을 update 하면서 discrimintative feature들을 얻을 수 있다. $||p-G_cw_c||^2_2$는 $p$가 선택된 모든 sub-feature map 과의 근접함을 알 수 있다. $\alpha^TG_cw_c$는 p와 각 sub-feature map과의 거리를 줄여주는 것을 목표로 한다.
위의 2개 개념은 deep feature들의 구별성을 증가시켜 준다. 따라서, $p$와 $G_c$로 $L(\theta)$를 미분 하면
$$
\begin{cases}
& \frac{\partial L(\theta)}{\partial p}=2(p-G_cw_c)-\alpha G_cw_c \newline
& \frac{\partial L(\theta)}{\partial G_c}=-2(p-G_cw_c)w_c^T - \alpha w_c^T.
\end{cases}\
$$
$p$와 $G_c$는 같은 FCN 파라미터 $\theta$를 공유한다. 그림 3과 같이 연쇄적으로 구해진다. 그 후에 SGD로 FCN이 학습이 된다. 학습 알고리즘은 Alogorithm 1에서 볼 수 있다
본 논문에서는 통합된 프레임워크를 설명했으며, softmax loss와 비교해서 전체 얼굴에서 임의의 얼굴 이미지 사이 거리 정보를 더 잘 표현할 수 있다고 한다.
4.Experiments
Network Architecture.: VGGFace에서 non-convolutional layers들을 다 제거하고 13층의 convolutional layers을 사용하였다. 마지막 pooling layer은 feature extractor이다. 표 1에서 전체 구조를 확인 할 수 있다.
Training and testing. : 그림 4를 보면 전체적인 구조를 볼 수있다.
- 16GB RAM, i7-4770 CPU @ 3.40GHz 장비를 사용함.
- CASIA-WebFace dataset에서 FCN과 sliding loss를 사용함.
- 각 랜덤 사이즈의 얼굴 이미지와 5개의 전체 얼굴 사진이 1그룹으로 2000개의 그룹이 존재한다.
- batch는 20 $10^{-4}$의 learning rate, $\alpha=0.6, \beta=0.4$
test를 진행 할 대는, probe와 gallery를 1가지 셋으로 사용하였다. FCN으로 특징을 추출하고 식 3과 식 7을 통해 얼굴인식을 진행하였다.

Evaluation Protocol: 제한한 방법의 성능 평과를 위해 Cumulative Match Characteristic (CMC) curve 실험과 Receiver Operationg Characterisitc (ROC) curve 실험을 진행하였다.
Databases and Settings.
- 학습에 partial-LFW를 사용하였다. LFW는 7,749명의 13,233 이미지가 포함되어 있는데, 많은 장애요소 (조명, 방해물, 각도 등)이 있따. 따라서, gallery face image는 $224\times224$로 재조정하고 probe는 전체 얼굴 이미지에서 랜덤으로 잘라서 사용한다.

- evaluation에는 partial-YTF를 사용하였다. YTF는 1595명의 3,424개의 비디오들이 포함되어있다. gallery는 200명에 대한 200개의 얼굴 이미지로 사용했으며, probe는 임의의 크기로 전체 얼굴에서 잘라서 사용한다.
- CASIA-NIR-Distance dataset 또한 evaluation에 사용한다. partial face image인 동시에 여러 각도와 크기 그리고 빛 상태를 가진다. 그림 5에서 확인 할 수 있다.
4.2 Experiment on LFW
4.2.1 Comparison to the State-of-the-Art
SOTA 비교를 위해 4개의 SOTA와 비교를 했다.
-
Multi-Scale Region-based CNN (MR-CNN) 10, MKDSRC-GTP 43, I2C 11 그리고 probe를 $224 \times 224$로 re-scaling한 VGGFace 이다. 본 논문에서 DFM은 $\alpha=2.1$ and $\beta=0.1$ 이다.
4.2.2 Face verification on LFW
표 2를 보면 DFM의 성능을 볼 수 있다. keypoint 기반의 알고리즘은, no robust하기 때문에 적절하지 않고, MR-CNN의 경우 alignment가 필요하며 CNN을 사용하지만 들인 시간만큼 성능이 나오지 않는다. 특히, 전통적인 방법으로는 임의의 크기를 가지는 얼굴 이미지들을 고정된 이미지로 조정해야한다.
$224 \times 224$ VGGFace는 DFM보다 성능이 낮은데, 크기를 바꾸면서, 불필요한 기하학적 변형이 일어나기 때문이다. DFM은 변형없이 공간 정보를 유지한다. - Face verification은 얼굴 이미지 짝으로 부터 같은 사람인지 아닌지 확인하는 기술이다. 본 논문에서는 LFW의 test protocol을 사용했다. 데이터셋을 cross-validation으로 10개의 subset으로나누고 각 subset은 300개의 진짜/가짜를 이룬다. 부분 얼굴 이미지를 위해 임의의 크기로 랜덤하게 자른다.

그림6은 다양한 PFR 알고리즘에 대한 ROC curve를 나타낸다. DFM은 다른 알고리즘에 비해 제일 좋은 성능을 보이며, 0.19ㅊ초라는 획기적인 속도를 보여준다.
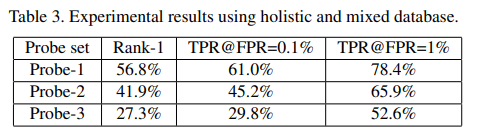
4.2.3 Evaluation on holistic face images and mixed partial and holistic face images
LFW에 대해 추가적인 실험을 진행햇는데, 총 3가지 그룹으로 나눠서 했다.
- Probe-1: 1000개의 전체 얼굴 이미지
- Probe-2: 500개의 전체 얼굴 이미지와 500개의 부분 얼굴 이미지
- Probe-3: 1000개의 부분 얼굴 이미지
표 3에서 결과를 보여주고 있다.
4.2.4 Influence of the cropped region size and the area

그림 7은 다른 크기의 얼굴 이미지에 따른 결과를 나타낸다.

그림 8은 어굴이미지의 다른 영역의 예제를 보여준다.
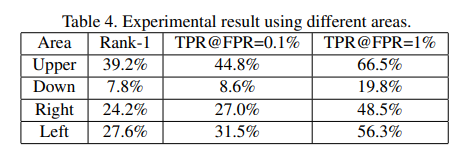
표 4는 그림 8의 예제를 가지고 실험한 결과를 보여준다.
위의 결과가 나오는 것은 당연하다. 잘라진 이미지는 더 적은 공간 정보를 갖고 있기 때문이다. 하지만, 눈 위로의 정보를 가질 경우, identification에 있어 좋은 성능을 보인다.
4.2.5 Parameter Analysis
similarity-guided constraint 인 $\alpha$와 sparsity constraint 인 $\beta$에 대한 실험도 진행했다. $\alpha$의 경우 0에서 4.2까지 0.3만큼 조절 했으며, $\beta$의 경우 0.1에서 1까지 0.1씩 조절했다. 그림 9는 DFM에 대한 $\alpha$와 $\beta$의 영향을 보여주면 best 는 $\alpha=2.1$과 $\beta=0.1$이다.
4.3 Partial Face Recognition on CASIA-NIR-Distance and Partial-YTF
CASIA-NIR-Distance와 Partial-YTF에 대한 성능 비교를 실험하였다. DFM, MKDSRC-GTP, RPSM, I2C, VGGFace 그리고 FaceNet에 대한 비교이다. 밑의 표 5를 보면 확인할 수 있다.
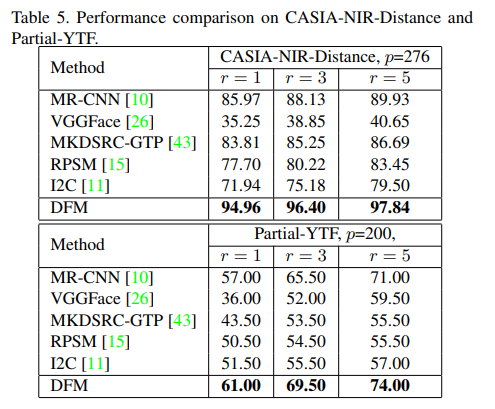
1) key-point 기반의 알고리즘은 부분 얼굴 인식에서 robust하지 못하기 떄문에 성능일 떨어지는 것으로 보인다.
2) VGGFace의 경우 고정 이미지로 변환하는 과정에 변형이 일어나 성능이 내려가는 것으로 보인다.
5. Conclusion
FCN은 모호한 입력사이즈로 부터 계산량 공유를 통해 부분적인 featur들을 생산한다. 또한 SRC를 사용해 alignment-free matching을 가능하게 했으며 FCN이 만든 feature를 잘 구별하는 DFM에 근거한 sliding loss를 제안했다.