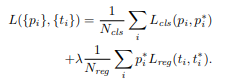단일의 deep neural entwork로 object detection을 구현했습니다. SSD라고 불리는 접근법은 다양한 크기와 비율을 가진 default box들로 각 feature map에서 bbox를 뽑아냅니다. predict를 할 때는 네트워크가 각 default box가 각각의 사물 카테고리에 속하는 score와 사물 모양에 잘 맞는 box를 만들어 냅니다. 게다가, 다양한 크기를 가지는 사물을 매끄럽게 변환한 다양한 feature map들을 결합하여 predict에 사용합니다. 쉽게 보면 object proposal들을 사용하는 방법들과 다릅니다. 그 이유는 proposal을 생성하는 부분과 pixel 또는 feature를 리샘플링하는 부분이 제거했으며 모든 계산을 단일 네트워크에서 진행합니다. 단일 네트워크로 학습을 쉽게 할 수 있고 detection에 필요한 요소를 통합했습니다.
결과로는 VOC2007에서 74.3%의 정확도와 59fps가 나왔다고 합니다.
Introduction
당시에 SOTA는 Faster-rcnn이었습니다. 정확도도 높고 deep 한 network입니다. 하지만 계산량이 너무 많으며 좋은 하드웨어를 사용해도 실시간으로는 사용하기 어렵다. 제일 빨라봤자 7 fps 밖에 나오지 않는다. 따라서 속도를 올리려고 노력했지만 속도가 올라간 만큼 저확도가 감소하였다.
본 논문은 object proposal를 사용하지 않고 object detection을 할 수 있으며 VOC2007 test를 기준으로 Faster R-CNN의 경우 7 fps, 73.2%이며 YOLO의 경우 45 fps, 63.4%이다. 본 논문에서 소개하는 SSD의 경우 59 fps, 74.3%의 결과를 가져왔다고 합니다. 즉, 속도와 정확도 두 마리의 토끼를 동시에 잡았습니다. 우선 proposal생성과 resampling 단계를 제거하여 속도를 증가시켰습니다. 또한 정확도를 위해 다른 scale과 aspect ratio를 가지는 default box를 사용하였습니다. ( Faster-RCNN의 Anchor와 유사) 그 후에 다른 크기들의 feature map을 prediction에 사용하였습니다.
YOLO 보다 빠르고 Faster-RCNN 보다 정확한 SSD를 소개합니다.
SSD의 핵심은 작은 conv filter들을 사용한 default box들을 여러 feature map에 적용시켜 score와 box 좌표를 예측합니다.
정확도를 높이기 위해서 여러 크기의 다른 feature map들로부터 여러 크기의 predict를 수행하고 비율 또한 다르게 적용했습니다.
end-to-end 학습을 할 수 있게 구축했으며 저해상도 이미지에서도 높은 정확도를 가집니다.
여러 대회(PASCAL VOC, COCO, ILSVRC)에서 실험을 진행한 것을 소개합니다.
The Single Shot Detector(SSD)
2.1은 SSD의 model을 설명하고 2.2는 학습 방법론에 대해 설명하겠습니다.
2.1 Model
SSD는 NMS를 거쳐 최종적으로 나오는 bbox와 score를 포함한 box들을 생각하는 feed-forward convolutional network(FFCNN)를 기반합니다. 밑의 그림은 단순한 FFCNN입니다. ( 원래 더 거대하다.)
앞의 네트워크는 base network라고 불리는데 조금 수정한 pre-trained conv network이다. 그리고 detection을 위해 몇 가지 구조를 추가했는데 밑에서 설명하겠습니다.
Multi-scale feature maps for detection
base network에서 끝이 생략된 conv feature layer를 추가했습니다. 이 layer들은 점진적으로 크기가 줄어들고 다양한 크기에서 prediction 하도록 했습니다. detection을 위한 convolutional model은 Overfeat 그리고 YOLO 같이 단일 크기의 feature map을 만드는 다른 feature layer입니다.
Convolutional predictors for detection
각각 더해진 feature layer은 prediction을 위해 conv filter가 사용된 세트를 만듭니다. 즉, 밑의 사진에서 SSD 네트워크 구조의 윗단을 가리킵니다.
m x n x p의 feature layer을 얻기 위해 각 conv layer로 부터 3 x 3 x p의 conv layer을 추가로 통과시킵니다. 즉, m x n 의 위치에 3 x 3 x p 의 kernel을 적용시킵니다. 이것을 detection에 사용합니다. bbox는 default box의 위치로 알 수 있습니다.
Default boxes and spect ratios
여러 개의 feature maps을 얻기 위해 각 feature map 당 default b box들을 적용했습니다. 위의 그림에서 각 con layer의 최상단에서 detections로 넘어갈 때 default box들에 적용했습니다. 각 feature map에 맞게 default box들 또한 바뀌어 적용합니다.(feature map cell이라고 불립니다.)
각 feature map cell은 classfier score 뿐만 아니라 box의 좌표 또한 예측할 수 있습니다. 즉, feature map cell에서 k개의 box를 가진 다고 하면, c개의 classifier score와 4개의 box 좌표를 계산해야 합니다. 즉 (c+4) k의 필터가 필요합니다. 여기서 만약 feature map이 m x n을 가진 다고 하면, (c+4)kmn의 파라미터를 가집니다.
default box의 예시는 첫 번째 그림에서 볼 수 있습니다. 이 default box는 faster RCNN의 anchor와 비슷합니다. 하지만, 각 default box를 여러 개의 feature map에 적용시켰습니다. 각각의 feature map 마다 default box를 가지는 것은 물체의 크기와 비율이 달라져도 효과적으로 대응할 수 있습니다.
2.2 Training
SSD와 여타 다른 detector과 크게 다른 점은 gt 정보가 고정된 detector 출력들에 특정한 출력으로 할당해야 하는 것이다. 이런 것은 VOLO, Faster RCNN, MultiBox에도 똑같이 필요하다. 할당되는 게 한번 정해지면, 손실 함수와 역전파는 end-to-end로 적용된다. 학습에는 default box들의 크기와 비율을 선택하는 것뿐만 아니라 negative mining과 data augmentation 방법들도 선택해야 한다.
Matching strategy
학습을 하는 동안, default box는 gt box와 대응하여 network가 학습된다. 따라서, default box들의 위치, 크기 그리고 비율은 다양하게 선택되어야 한다. MultiBox의 최고 jaccard overlap과 함께 gt box와 default box를 매칭 시켰다. MultiBox와는 다르게 threshold인 0.5보다 크게 잡았다. 이렇게 하면 좀 더 정확하게 겹쳐야 default box가 선택이 된다. 즉, 학습을 좀 더 단순화시킨다.
가 있다고 하자. 여기서 i는 default box의 index, j는 gt box의 index, 그리고 p는 object의 index이다. 위의 _Matching Strategy_을 적용시키면
를 예측할 수 있다.
결국엔 전체 손실 함수는 localization loss (loc)와 confidence loss (conf)의 합으로 나타난다.
N : gt box와 매칭 된 default box의 개수 ( N이 '0'이면 loss 또한 '0'이다.)
l : 예측한 box
g : gt box
c : confidence score(물체일 확률)
loc는 l과 g을 파라미터로 가지는 Smooth L1 loss function이다.
α : weight term이며, cross validataion에서 1로 설정된다.
Faster-RCNN과 똑같이 box들의 좌표는 중심 좌표(cx, cy), 너비(w), 그리고 높이(h)를 가진다.
g^은 gt box와 default box의 차이를 뜻한다.
conf의 경우는 c를 파라미터로 가지는 softmax loss function이다.
Choosing scales and aspect ratios for default boxes
다른 크기와 비율의 object를 인식하는 방법에는 여러 가지가 있다. 4, 9, 10, 그리고 11가 있다. 본 논문에서는 여러 가지의 크기와 비율을 가진 default box들을 이용한다. 다른 차원의 feature map들을 사용한 네트워크는 성능이 좋습니다. SSD 또한 다른 차원의 feature map을 사용합니다. 위의 _Convolutional predictors for detection_의 그림에서와 같이 다른 차원의 feature map에서 default box를 가져와 인식에 사용합니다.
m : feature map의 개수.
s : default box들의 크기
min : 0.2 ( 가장 낮은 차원의 feature map 크기)
max : 0.9 ( 가장 높은 차원의 feature map 크기)
결과적으로 1 셀당 6개의 default box들이 생겨난다. 만약, 5x5 feature map이라고 하면 5x5x6x(c+1)의 박스가 생겨난다.
더 큰 feature map에서는 작은 object를 더 작은 feature map에서는 큰 object를 인식할 수 있다. 그 이유는 셀이 많은수록 default box의 크기가 작아 object가 크다면 인식하지 못하기 때문이다.
Hard negative mining
matching 단계가 지난 후에는 대부분의 default box들은 negative 일 것입니다. 이것은 positive와 negative 학습 데이터의 언밸런스 문제로 이어집니다. 따라서 모든 negative 데이터를 사용하는 것이 아니라 negative : positive = 3:1 로 사용합니다. 본 논문을 제작한 분들이 이 비율이 제일 optimal 하다고 합니다.
data augmentation
input으로 사용할 object는 다양한 크기와 모양이 필요합니다. 따라서
0.1, 0.3, 0.5, 0.7, or 0.9의 jaccard overlap을 사용합니다.
무작위로 sample들을 사용합니다.
각 sample을의 크기는 기존의 이미지의 0.1 에서 1배의 크기를 가지며 비율 또한 2배 또는 1/2배 입니다. 물론, 이미지의 중앙을 기준으로 적용시킵니다. 위의 샘플링 작업이 끝난 뒤, 원래의 크기로 resize 하고 50%의 확률로 뒤집어 적용시킵니다. 마지막으로는 14처럼 왜곡을 적용합니다.
3. Experimental Results
여기에서는 실험 결과가 아니라 여러 실험을 통해 나온 팁을 적을 것입니다.
base network base network로는 VGG16을 적용시켰다고 합니다. 하지만 완벽하게 그대로 사용한 것이 아니라 layer를 조금 변형시켜 적용했다고 합니다.
3.2 Model analysis
Data augmentation이 중요합니다.
data augmentation을 적용시켰을 때 8.8%의 성능이 향상되었다고 합니다.
변형한 VGG16이 빠릅니다.
SSD에서는 VGG16을 사용했는데 완전하게 쓴 것이 아니라 conv11_2를 제거하고 사용하였다. 그렇게 진행하니
여러 feature map을 사용하는 것이 성능을 향상시킵니다.
위의 표에서 6개의 feature map을 사용하는 것이 아닌 마지막 feature map을 사용하지 않고 5개의 feature map을 사용하는 것이 더 좋은 성능이 나옵니다.
5. Conclusions
SSD는 multiple categories 1-stage detector이다. 제일 큰 특징은 여러 개의 featuremap으로부터 다양한 크기의 bbox를 가져오는 것이다. 이것이 매우 효과적으로 성능 향상에 도움이 되었다. 다른 obejcet detector(faster rcnn, yolo 등)와 비교하여 높은 인식률과 속도를 보여줍니다. 마지막으로 rnn이나 영상에서 object tracking에서도 잘 사용될 것이다.
이때 당시 SOTA는 SPPnet 과 Fast R-CNN 입니다. bottleneck 같은 region proposal(RP) 계산을 사용합니다. 본 논문에서는 Region Proposal Network(RPN)을 소개합니다. RPN이란 전체 이미지를 CNN시킨 feature map을 공유하는 네트워크로 RP를 cost 부담 없이 사용할 수 있다고 합니다. (Free Time and Accuracy)
RPN은 Fully Convolutional Network로 각 지점에서 Bbox 와 classifier을 동시에 예측할 수 있다고 합니다. 여기서 중요한 점은 Fast R-CNN이 detection 하는 것을 그대로 가져왔으며 단지 바뀐점은 RP를 RPN을 이용하는 것입니다. 결국, 이 논문은 RPN과 Fast R-CNN을 feature map을 공유하는 한 개의 네트워크로 합친 것입니다.
성능은 뒤에서도 설명하겠지만, backbone으로는 VGG-16을 사용하고 PASCAL VOC 2007 test set에 대한 결과로 79.2%mAP가 나왔습니다.(train set은 VOC 2007+2012 trainval을 사용 하였습니다.) 속도는 모든 단계를 포함해도 이미지당 198ms이 나온다고 합니다.
1. Introduction
R-CNN - Fast R-CNN - Faster R-CNN으로 이어져 왔습니다.
Selective Search(SS)의 경우 RP를 찾는 유명한 방법이지만 이미지당 2초씩 계산 시간이 걸리기 때문에 real-trime object detection에는 적합하지 않습니다.
EdgeBoxes라는 이미지당 0.2초가 걸리는 방법이 나왔지만 결국엔 detection 부분에서 여전히 오래 걸립니다.
이유로는, RP를 찾는 부분에서 GPU가 아닌 CPU를 사용해야합니다. GPU로 재구현하는 방법이 존재합니다.
하지만 이 또한 down-stream detection network를 무시하는 것과 sharing computation(공유 계산...? 계산한 것을 공유한다는 뜻인 것 같습니다.)를 하지 않는 문제가 있습니다.
이 논문에서는 위의 문제들을 우아하게(?) 알고리즘적으로 해결했다고 합니다
바로, RPN입니다. 즉, 테스트 시간에 convolution들을 공유한다면 가장 끝에서 계산 시간이 줄어들 것이라고 합니다. (여기선 이미지당 10ms가 걸린다고 합니다.)
Fast R-CNN에서 feature map이 RP로 사용될 뿐만 아니라 RP를 생성하는 것을 봤습니다. 따라서, 막 feature map이 만들어졌을 때, RPN을 feature map으로 쌓아서 만들고 각 지점을 정형화된 grid로 나눈다면 bbox와 classifer을 동시에 할 수 있을 것이라고 생각했습니다. 즉, RPN은 fully convolutional network와 비슷한 것이며 detection proposal들을 만드는 것을 end-to-end로 학습할 수 있다고 합니다.
RPN은 SPPnet이나 Fast R-CNN과 같은 일반적인 방법들과는 달리 다양한 scale과 aspect ratio에서도 RP를 효과적으로 예측할 수 있도록 만들어졌다고 합니다.
일반적으로 (a)나 (b) 같은 방법으로 다양한 scale과 aspect ratio에서 RP를 예측한다고 합니다.
본 논문은 (c)와 같은 방법으로 Archor라는 다양한 scale과 aspect ratio를 가진 참고 박스를 소개합니다.
즉, 여러 크기의 이미지를 열거하거나(a) 많은 scale 또는 aspect ratio들을 사용하는 것(b)보다 단일 scale의 이미지를 사용하는 것(c)이 효과적이며 빠릅니다.
본 논문의 RPN은 RP를 위한 fine-tuning과 object detection을 위한 fine-tuning을 선택적으로 학습시킬 수 있습니다. 또한, 빠르게 수렴합니다.
본 논문은 포괄적으로 평가하였는데,
PASCAL VOC detection benchmarks에서 SS와 RPN을 비교 ( with Fast R-CNN) => SS와 비교해 proposals들을 생성하는데 단지 10ms만 걸렸다.
very deep network의 문제인 시간 부하를 모든 단계를 다 포함해도 5fps의 성능이 나온답니다. 물론, 속도와 정확도를 버리지 않고도 작동함. (GPU를 사용할 경우)
MS COCO dataset에 대해 결과를 연구하였다.
ILSVRC 와 COCO 2015 대회에서 ImageNet detection, ImageNet localization, COCO detection, 과 COCO segmentation 에서 1등을 했다고 합니다.
Object Proposal 기법은 SS를 이용한 object detection, R-CNN, 그리고 Fast R-CNN에서 사용되었습니다.
2-2. Deep networks for Object Detection
R-CNN은 기본적으로 CNN들의 end-to-end로 학습을 하여 배경 또는 사물들인지 RP를 통해 판별합니다. 또한, 기본적으로 classifier로 동작하지 object bound을 예측하지는 않습니다. (물론, bbox 회귀는 제외합니다.) 따라서, RP 모듈에 의해서 성능이 좌지우지됩니다. (참고 문서 : comparisons)
Overfeat 기법에서 fully-connected 층은 단일 사물의 위치를 boxing하는 예측을 위해 학습됩니다. 즉, 한 image안에 여러개의 사물이 있을 경우 각 사물마다 bounding box를 생성하는 역활입니다. 또한, 여러 사물을 찾는 convolutional 층을 조정하는데 사용됩니다.
MultiBox 기법( 위에서 Overfeat를 제외한 논문들 )은 fully-coonected 층을 Overfeat 기법처럼 다수의 사물을 동시에 예측하는 네트워크로 사용하며 RP를 추측합니다. 또한, MultiBox proposal 네트워크는 fully-connected 층을 사용하기 보단 단일 이미지 모음 또는 다중 이미지 모음을 사용합니다. (보통 224x224) 또, proposal 과 detection 네트워크의 feature를 공유하지는 않습니다.
** 아마도, overfeat의 장점과 MultiBox 장점을 다 가진다는 것을 표현하고 싶었던 것 같습니다.**
convolution들의 계산을 공유하는 Overfeat, SPP, Fast-RCNN, 7, 그리고 semantic segmentation 들은 시각 인식 분야에서 정확도 같은 효율성에 관심을 가졌다. Overfeat 기법은 classfication, localization, 그리고 detection을 위해 이미지 피라미드로 부터 convolutional feature를 계산하였다. SPP의 feature map을 공유하는 adaptively-sized pooling, 30 그리고 semantic segmentation 또한 효과적인 region 기반의 object detection 이다.
밑의 사진은 SPP에 대해 짤막하게 설명한다. 즉, featurn map을 crop과 resize를 통해 detection 하는 것입니다.
마지막으로 Fast R-CNN은 feature map을 공유하여 end-to-end detector 학습이 가능하며 정확도와 속도가 높다.
3. Faster R-CNN
Faster R-CNN은 2개의 모듈로 이루어져있습니다. 첫번째 모듈은 PR을 만드는 deep fully convolutional network 이며, 두번째 모듈은 Fast R-CNN detector 처럼 PR을 사용하는 것입니다.
3-1 에서는 RPN의 구조와 요소 를 소개할 것이며 3-2에서는 feature shared 모듈을 개발하는 알고리즘을 볼 것입니다.
3-1. Region Proposal Networks
RPN의 입력은 이미지이며 출력은 사물 점수를 포함한 사각형의 object proposal 셋이다. 즉, classifier와 bbox가 된 것입니다. 본 논문에서 fully convolutional 층을 semantic segmentation의 fully convolutional 층처럼 만들었습니다. 또한, 두 네트워크를 같은 convolutional 층들로 사용했는데, 그 이유는 Fast-RCNN처럼 계산을 공유하기 위해서입니다. 실험에서는 ZF와 VGG-16을 사용했다고 합니다.
RP을 뽑아내기위해, 최초의 convolutional 층들의 마지막 단에서 작은 네트워크로 분리했습니다. (위의 그림에서 proposals 부분) 이 작은 네트워크는 feature map을 n x n으로 나눈 window를 입력으로 가집니다. 각 슬라이딩 윈도우는 33에서 처럼 더 작은 차원의 feature와 맵핑됩니다. 이 feature은 다시 또 두개의 fully-connected 층들의 입력으로 들어가는데 box-regression layer(reg) 와 box-classification layer(cls)이다. 본 논문에서 n은 3으로 정하여 사용하는데, ZF 나 VGG-16에서 잘 작동하기 떄문이다.
나눠진 네트워크는 위의 그림처럼 생겼다. 미니 네트워크는 슬라이딩 윈도우 만듦새를 사용하기 때문에 fully-connected layer들은 모든 부분 위치에서 공유된다. 즉, 위의 사진에서 저 부분에서 나온 feature들이 cls 와 reg에서 공유한다는 뜻이다. 이 구조는 자연스럽게 n x n conv layer를 거쳐 두 개의 1 x 1 conv layer로 구현된다.
3-1-1. Anchors
각 슬라이딩 윈도우 위치에서 동시에 여러 RP들을 예측할수 있는데 최대 k개 입니다. 따라서 reg 층에서는 k개의 박스들에서 4k개의 박스 요소 출력을 가지며, cls 층에서는 각 proposal에서 사물일 확률과 배경일 확률 총 2k개의 출력을 가집니다. 이 k개의 proposal들은 anchor라고 부르는 k개의 참고 박스를 매겨변수로 가집니다. 앵커는 슬라이딩 윈도우의 중심좌표를 가지며, scale과 aspect ratio와 관련이 있습니다. default 값으로 3개의 scale과 3개의 aspect ratio인데, 각 슬라이디 윈도우마다 k=9개의 앵커를 가지는 것입니다. 보통 feature map은 W x H(~2,400)이므로, 결국 W x H x K의 앵커들을 가집니다. ex) if w = h = 2400, k = 9 ==> 51,840,000개의 앵커를 가집니다.
Translation-Invariant Anchors
짧게 설명한다면 이 앵커라는 개념은 본 논문에서 중요하다고 합니다. Multibox 방법은 k-means를 사용해서 800개의 앵커들을 만들어 낸다고 합니다. 하지만 이 앵커들은 사물이 바뀌면 제대로 작동이 안 된다고 합니다. 즉, 사물 당 800개 정도의 앵커들이 필요하다는 것입니다. 본 논문의 경우 9개의 앵커만 필요합니다. 이것은 모델의 크기를 줄이는 역할을 합니다. 밑의 표를 살펴보면 차이가 많이 납니다.
content
Multibox
Faster-RCNN
fully-connected output layer size
(4+1) x 800
(4+2) x 9
본 논문에서는 Faster-RCNN에 VGG-16 모델을 사용하고 Multibox에 GoogleNet을 사용했습니다. 음... 같은 모델을 사용했으면 좋을 거 같은데... 따라서 결과적으로
content
Multibox(GoogleNet)
Faster-RCNN(VGG-16)
parameters
1536 x (4+1) x 800
512 x (4+2) x 9
따라서... 파라미터가 적어서 PASCAL VOC 같은 작은 데이터 셋에서 오버 피팅이 발생을 줄인다고 합니다.
Multi-Scale Anchors as Regression References
(a) DPM 이나 CNN 기반은 방법들은 이미지 당 featuremap이 피라미드 형태입니다. 이미지들을 여러 크기로 만들고 그 이미지 마다 feature map들이 존재한다. 따라서 각 이미지 마다 계산을 해줘야 합니다. 이 방법은 유용하지만 시간이 너무 오래 걸립니다. (b) feature map에서 많은 크기와 비율의 슬라이딩 윈도우를 사용하는 방법입니다. 예를 들면, DPM에서는 비율이 다른 슬라이딩 윈도우를 사용하는데 5 x 7 그리고 7 x 5를 사용합니다. 이 방법은 (a)보다 성능이 좋아 다른 object detection에서 사용됩니다.
위의 방법들과 비교해서 앵커 피라미드를 사용하는 것이 매우 효과적입니다. cls와 reg에서 앵커 박스들을 참조합니다. 오직 앵커 박스는 단일 크기의 feature map에 적용됩니다. 즉, 1개의 슬라이딩 윈도우당 k개의 앵커 박스가 존재하는 것입니다. 본 논문에서는 3가지의 크기와 3가지의 비율을 가진 총 9개의 앵커 박스를 사용했습니다. 크기의 경우 128x128, 256x256, 512x512을 사용했으며 비율의 경우 2:1, 1:1, 1:2를 사용했습니다.
따라서, 다양한 크기의 앵커 박스를 사용함으로써 다른 cost(공간이든 시간이든) 없이 특징들을 공유할 수 있습니다.
3-1-2. Loss Function
RPN의 학습을 진행할 때, 각 앵커에 positive or negative의 라벨을 달아줍니다. positive 라벨에는 두 가지 경우가 있는데
Ground-Truth box와 가장 높은 IoU를 가지는 경우
IoU가 0.7 보다 높은 경우
이런 경우 한 개의 GT box가 여러개의 앵커에 positive 라벨을 달아줄 수 있습니다. 보통 2번째 조건까지하면 posivive 샘픔가 나오는데 positive 샘플이 없는 특별한 경우가 발생할 수 있습니다. 따라서 밑의 조건을 더 추가합니다.
IoU가 0.3 보다 낮을 경우 negative 라벨을 달아준다.
마지막으로 0.3<IoU<0.7의 샘플들은 학습 데이터로 사용하지 않습니다.
이런 방법들로 objective function은 Fast R-CNN의 multi-task loss를 따릅니다. 밑은 이미지당 가지는 손실 함수의 정의입니다.
i : batch 당 앵커의 인덱스. pi : 앵커 i가 사물로 인식한 확률. (score) pi*: Ground-Truth 라벨. ( 1: positive, 0: negative) ti: bbox의 좌표(보통 중앙의 x, y, w, h) ti*: Ground-Truth의 bbox 좌표 Lcls: classification loss. 사물인지 배경인지(둘 score) Lreg: Regression loss. 다시 밑의 수식으로 나뉨. $$ Lreg(ti, ti_) = R(ti - ti_) $$ R: robust한 손실 함수.(smooth L1) pi*Lreg: positive일 때 작동한다는 뜻.
각각 cls와 reg의 출력은 {pi}, {ti}로 이뤄져 있다. Ncls 와 Nreg에 의해 표준화되며, λ에 의해 균형잡힌 가중치가 나옵니다. 보통 Ncls = 256, Nreg = ~2,400, λ = 10 으로 지정되어 있습니다.
밑의 수식은 bbox regression에서 t들에 대한 정의입니다.
x,y,w,h 는 중심의 x,y좌표와 박스의 너비와 높이입니다.
0, 0a, 0* 는 각각 예측한 박스, 앵커 박스, GT 박스 의 값를 뜻합니다.
따라서 이 수식은 앵커 박스를 통해 GT 박스로 근접해 가는 것으로 볼 수 있습니다.
그렇지만 Resion of Interst(RoI: 관심 영역) 기반의 방법들인 R-CNN이나 Fast R-CNN과는 다른 방법으로 bbox regression을 얻었다. 기존의 방식들은 임의의 RoI 크기를 사용했으며 모든 region이 같은 regression weight를 사용한다. 보통 3 x 3 크기의 feature map들을 사용한다.
본 논문은 다양한 크기들에서도 detection 하기 위해 k 개의 bbox regressor를 학습시켰다. 각 regressor은 단일의 크기와 비율을 가지는데 k 개의 regressor은 가중치를 공유하지 않는다. 따라서 앵커들로 구현하여 feature들이 다른 크기나 비율을 가지더라도 detection 할 수 있는 것이다.
3-1-3. Training RPNs
RPN은 backpropagation 과 Stochastic Gradient Descent(SGD : 확률 경사 하강법) 을 통해 end-to-end 학습이 가능하다. Fast-RCNN과 같이 이미지의 중심으로 샘플링을 한다. 각 mini-batch는 많은 positive 와 negative 앵커가 포함된 이미지가 생기게 합니다. 모든 앵커들을 손실 함수로 최적화가 가능하지만, negative 샘플들로 치우치게 됩니다. 대신에, mini-batch의 손실함수로 사용하기 위해 무작위로 positive 와 negative 샘플들을 1:1 비율로 256개 앵커를 뽑아냅니다. 만약, positive 샘플이 128개(50%)보다 적다면, negative 샘플들로 채웁니다.
무작위로 모든 layer들을 생성하며 가중치는 0-평균 Gaussian ditribution(표준 편차 0.01)로 초기화 합니다. (물론 RPN에서의 conv layer 입니다.) 모든 layer들은 ImageNet classification의 pre-training된 데이터로 초기화합니다. ZF net의 모든 층 그리고 conv3_1 와 학습된 VGG net으로 조정합니다. PASCAL VOC 데이터 셋에서 learning rate로는 0.001 (mini-batch 60k), 0.0001 (mini-batch 20k)으로 사용한다. momentum은 0.9, weight decay는 0.0005를 사용한다. 구현은 Caffe로 함.
3-2. Sharing Features for RPN and Fast R-CNN
위의 내용까지는 PR을 위한 RPN이였다. 실질적으로 Detection을 하는 부분에서는 Fast-RCNN과 동일하다. 밑의 박스친 부분이 Detection 부분이다.
RPN과 Fast-RCNN 둘다 독립적으로 훈련되어 각자 다른 방법으로 conv layer들을 수정한다. 따라서 이 두 네트워크가 따로 학습하는 것이 아니라 conv layer들을 공유하게 하기 위해서 밑의 3가지 방법을 소개 합니다.
3-2-1. Alternating Training
이 방법은 본 논문에서 사용된 방법으로 먼저 RPN을 학습하고 proposal들을 사용해 Fast R-CNN을 학습하는 것입니다. 즉, Fast R-CNN은 RPN으로 초기화된 네트워크를 사용하며 이 단계를 반복하는 것입니다.
3-2-2. Approximate Joint Training
RPN과 Fast R-CNN 네트워크를 병합하여 위의 사진에서 검은색으로 박스친 부분처럼 하나의 네트워크로 만드는 것입니다. SGD 단계가 반복할 때마다, 순전파 단계에서 PR을 생성할 때 Fast R-CNN detector가 학습하는 것처럼 고치고 미리 계산하는 것입니다. 역전파 단계에서는 RPN과 Fast R-CNN 둘다 손실이 결함된 형태로 역전파가 이루어집니다. 이 방법은 구현이 쉽지만, proposal 박스들의 좌표 값을 무시하고 근삿값을 사용한다. ( 이 부분은 잘 모르겠습니다..) 이 방법으로 실험해본 결과 alternating training 결과와 거의 근접했지만 학습시간이 25~50% 더 걸린다고 합니다.
3-2-3. No-approximate Joint Training
RPN으로 예측한 bbox를 함수의 입력으로 사용하는 것입니다. 즉, Fast R-CNN의 RoI pooling layer은 conv feature들을 입력을 받는데, 여기서 예측한 bbox 또한 입력으로 넣습니다. 이 방법은 이론적으로 Approximate Joint Training의 문제를 해결하는 것처럼 보입니다. 하지만, 이것은 proposal 박스들의 좌표 값을 무시하는 문제를 해결하지 않습니다. 따라서 RoI pooling layer을 preopsal 박스들의 좌표 값을 추출할 수 있게 해야합니다. 이 문제는 사소한 문제인데 RoI warping을 사용하면 됩니다. 이 방법은 15 논문에서 잘 설명하고 있습니다.
3-2-4. 4-Step Alternating Training
본 논문에서는 Alternating optimization을 통해 4 단계 학습 알고리즘을 사용합니다.
RPN을 먼저 학습한다. ImageNet-pre-trained 모델로 초기화하고 미세 조정을 거친다.
step-1의 RPN에서 만들어낸 proposal들을 사용하여 Fast R-CNN을 학습한다. 물론, Fast R-CNN또한 ImageNet-pre-trained 모델로 초기화한다. 아직까지는 두 네트워크가 conv layer들을 공유하지는 않는다.
detector network를 학습된 RPN으로 초기화 한다. 여기서 conv layer들을 공유할 수 있게 수정하고 오직 RPN의 특별한 layer들만 미세 조정한다. 여기서 두 네트워크가 conv layer들을 공유한다.
공유하는 conv layer들을 유지하면서 Fast R-CNN의 특별한 layer들만 미세 조정한다. 여기서 두 네트워크는 같은 conv layer들을 공유하고 통합된 네트워크를 형성한다.
실험 결과로, 위의 단계를 더 많이 반복해도 결과에 영향은 줄만큼은 아니였다고 합니다.
3.3 Implementation Details
먼저 SPP나 Fast R-CNN 처럼 단일 크기의 이미지를 사용하고 600pixel로 재조정했다고 합니다. 물론, 여러 크기의 이미지를 사용하면 정확도는 올라가지만 그만큼 속도가 더 떨어지기 때문에 손해입니다.
ZF나 VGG의 경우 마지막 단에서 1/16으로 줄어들며, 일반적인 PASCAL 이미지의 경우 500x375 크기인데 약 10pixel 정도로 줄어든다고 합니다. 그리고 작은 stride를 쓸수록 정확도가 높아진다고 합니다.
앵커의 경우 3개의 크기인 128², 256² 그리고 512² 를 사용하고 비율의 경우 1:1, 1:2, 2:1을 사용합니다. 앵커 파라미터 선택은 그렇게 중요하지 않습니다. 이미지 경계를 지나가는 앵커 박스는 조심해서 다뤄야 합니다. 학습을 진행하는 동안은, 앵커들끼리 교차 경계가 생기는 것은 무시합니다. 따라서 loss에 영향을 끼치지 않습니다. 일반적으로 1000 x 600 이미지는 약 20000개의 앵커를 가지고 있습니다. 이럴 경우, 이미지당 6000개의 앵커가 훈련에 사용됩니다. 이렇게 되면 학습을 진행하면서 지속적으로 앵커들이 쌓이고 나중에는 활용할 수 없을 정도가 됩니다. 그러나, 테스트를 하며서 fully convolutional RPN을 전체 이미지에 사용합니다. 이것으로 이미지 경계를 자른 교차 경계 proposal box들이 생깁니다. 몇몇의 RPN preoposal들은 서로 많이 겹쳐있습니다. 많이 겹쳐있는 박스들을 없애기 위해서 non-maximum suppression(NMS)라는 것을 cls을 기준으로 적용시킵니다. NMS의 IoU threshold를 0.7로 고치는데 약 2000개의 PR만 남게 됩니다. 즉, cls score가0.7 이하인 것은 다 지우는 겁니다. NMS 이후에, top-N로 순위가 매겨진 PR을 사용합니다. 이로써 Fast R-CNN 학습에는 2000개의 RPN proposal들이 사용되지만, 실제 테스트 시간에서는 몇 개의 proposal들만 사용됩니다.
Experiments
실험 결과에 대해서는 따로 언급하지 않겠습니다.
Conclusion
RPN으로 효과적이고 정확하게 RP를 만들 수 있습니다. detection 네트워크에 conv feature들을 공유하면서 RP 단계가 거의 자유롭게 할 수 있습니다. 본 논문의 방법은 통합되고, 딥 한 object detection을 실시간 시스템을 가능하게 합니다. 즉, RPN으로 RP 질을 높일 수 있으며 이로 인해 전체 object detection 정확도가 올라갑니다.