Loss Function Search for Face Recognition
Abstract
AutoML로 인해 성능좋은 AM-LFS 것처럼 hand-crafted loss function은 sub-optimal이다. 본 논문은 softmax probability를 줄이는 것에 집중하여 margin-based softmax loss function을 만든다.
1. Introduction
Face Recognition은 얼굴을 구별하는 Face identification과 얼굴을 비교하는 Face verification이 있다. 여기서 loss function이 큰 역활을 한다. 크게 contrastive loss와 triplet loss와 같은 metric learning loss function와 classification loss function이 있다. metric learning loss function은 계산량이 많으며, 비교대상이 되는 샘플에 대해 성능에 큰 영향을 받는다.
직관적으로, face features은 intra-class compatness와 inter-class separability가 크면 클수록 더 쉽게 구분할 수 있다. 그래서, 기존의 softmax loss가 face features를 잘 구분하지 못한다는 말이 많았다. center loss와 몇몇의 softmax loss의 진화는 intra-class variance를 줄였으며, A-Softmax는 inter-class variance를 줄였다. 그러나 위의 방법들은 조심스럽게 파라미터들을 조정해야지 최적의 결과가 나온다. 또한, AM-Softmax loss나 Arc-Softmax와 같이 기하학적인 loss function도 있지만, 매우 큰 design space를 거쳐야하며 일반적으로 sub-optimal에 도달한다.
최근 AutoML을 통해 AM-LFS라는 loss function search method가 발표되었다. 이 논문은 loss funtion의 hyper-parameter를 매개변수화된 확률 분포 샘플링을 공식화하고 여러 vision task에서 좋은 결과를 가져왔다. 하지만, 이 방법은 intra-class distnace에서 inter-class distance의 상대적 중요성을 활용하여 탐색 공간의 디자인을 이끌어내는데 사용하지않아, 결과적으로 복잡하고 불안정하다.
따라서, 위의 단점을 보완하기위해 기존의 hand-crafted loss function의 장점들을 분석하여 적용해 더 효과적인 방법을 제안한다.
- "어떻게 하면 softmax probability를 줄일 수 있을까?"에 대해서 생각을 했다.
- 단순하지만 매우 효과적인 search space를 설정했으며, random/reward-guided method를 사용했다.
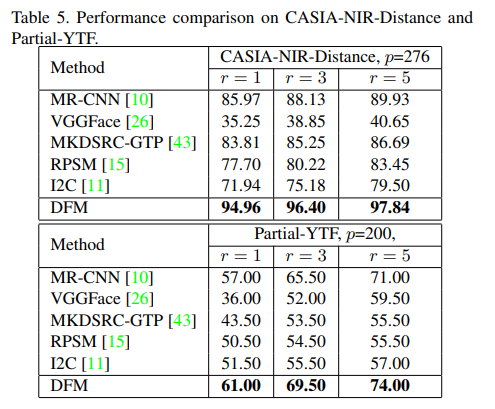
- LFW, SLLFW, CALFW, CPLFW, AgeDB, CFP, RFW, MegaFace 와 Trillion-paris 등등 많은 벤치마크에 대해서 비교 실험을 했다.
2. Preliminary Knowledge
softmax: softmax function + cross-entropy loss로 만들어져있으며, 밑의 수식과 같다.
face recongnition으로 오게되면 weights $w_k$와 feature $x$로 정규화되고 scale parameter $s$로 magnitunde가 대체되며 밑의 수식과 같아진다. 여기서 cosine similarity($cos(\theta_{w_k,x}) = w_k^Tx$)가 추가되어 face recognition의 구별성을 증가시켜준다.
Margin-based Softmax: 여러 margin이 추가된 loss function이 생겨났으며, A-softmax loss, Arc-softmax loss 그리고 AM-Softmax loss가 유명하다.
전체적으로 $f(m, \theta_{w_y},x)<cos(\theta_{w_y},x)$인 margin function을 가진다. 각각,
- A-Softmax loss: $f(m_1, \theta_{w_y},x)=cos(m_1\theta_{w_y},x)$ 와 $m_1\geq1$
- Arc-Softmax loss: $f(m_2, \theta_{w_y},x)=cos(\theta_{w_y},x + m_2)$ 와 $m_2>0$
- AM-Softmax loss: $f(m_3, \theta_{w_y},x)=cos(\theta_{w_y},x)-m_3$ 와 $m_3>0$
- 위의 것을 합친 loss: $f(m, \theta_{w_y},x)=cos(m_1\theta_{w_y},x + m_2) - m_3$ 존재한다.
AM-LFS: AutoML for Loss Function Search의 약자로 search space를 설정해 loss function을 찾는 논문이다.
$a_i$와 $b_i$는 search space의 매개변수이며 $i \in [0, M-1]$에 따라 사전에 분할된 softmax probability의 bin이다. M은 bin의 갯수를 나타낸다. 결과적으로 search space는 조각별 선형 함수(piece-wise linear function)를 사용하는 후보 집합으로 볼 수 있다.
3. Problem Formulation
본 논문에서 저자들은 margin-based softmax losses를 공식화하고 무작위성을 가진 reward-guided loss function search method를 만들었다고 합니다.
3.1 Analysis of Margin-based Softmax Loss
먼저 softmax probability를 다음과 같이 정의 한다.
그리고 margin-based softmax probability $p_m$은 다음과 같다.
위의 수식과 같이 유도되며 변조 인자인 $a$는 음수의 값을 가진다. ($a\leq0$)

표 1에 요약되어 있으며, $a=0$일 때, margin-based softmax probability $p_m$은 softmax probability $p$와 같다. 즉, 위의 $h(a,p)=\frac{1}{ap+(1-a)}\in (0,1]$로 모든 softmax probability를 표현할 수 있으며, 어떻게 하면 softmax probability를 줄일 수 있을까에 대한 답을 찾을 수 있을 것이다.
AM-LFS와 차별성이 3가지가 있다. 1) 본 논문의 수식인 $p_m$이 항상 softmax probability$p$보다 항상 작지만, piece-wise linear function 은 그렇지 않다. 즉, AM-LFS가 변별력을 항상 보장하지는 않는다. 2) 본 논문의 수식은 하나의 매개변수 $a$를 가지지만, AM-LFS는 2M개를 가진다. 즉, AM-LFS가 복잡하고 불안정하다. 3) 본 논문의 수식은 매개변수의 타당한 범위를 가지지만, AM-LFS는 제한이 없다.
3.2 Random Search
위의 분석을 그대로 수식 (2)에 넣어 통합된 공식을 만들었으며, 다양한 classes 사이에서 구별성 feature의 능력을 가질 수 있겠했다. 또한, search space를 $h(a, p)$로 정의할 수 있게 된다.
각 train epoch에서 변조 인자 $a\leq0$를 무작위로 설정하고 Random-Softmax로 표기한다.
3.3 Reward-guided Search
softmax probability를 줄일 수 있다면, feature discrimination이 강화되는 것으로 볼 수 있다. 하지만, 학습을 하는데 어떤 가이드라인이 없다면 최적은 아니다. 따라서, 이 문제를 해결하기위해 hyper-parameters $B={a_1,a_2,...,a_B}$ 로 각 학습 epoch의 분산을 주고 현재 모델을 학습하는데 사용한다. hyper-parameter $a$는 가우시안 분산을 이용한다.
1번의 학습이 완료된 뒤, B 모델들은 생성되고 이 모델의 reward $\mathcal{R}(a_i),\ i\in [1,B]$는 hyper-parameter $\mu$의 분산을 업데이트한다.
여기서 $g(a_i);\mu, \sigma$는 가우시안 분포의 PDF이다. 위의 방식으로 a의 분산을 업데이트하며 B의 후보들중 다음 epoch에 사용할 최고의 모델을 찾는다. 이것을 Search-Softmax라고 부른다.
3.4 Optimization
여기서는, Search-Softmax loss의 학습 과정을 보여준다. network model $\mathcal{M}_w$가 있다고 할 때, training set $\mathcal{S}_t = {(x_i, y_i)}_{i=1}^n$와 validation set $\mathcal{S}_v$ 각각에 대해 search loss는 최소화 하면서 rewards인 $r(\mathcal{M}_{w*(a)}, \mathcal{S}_v)$를 최대화 하는 것을 목표로 한다. 즉,
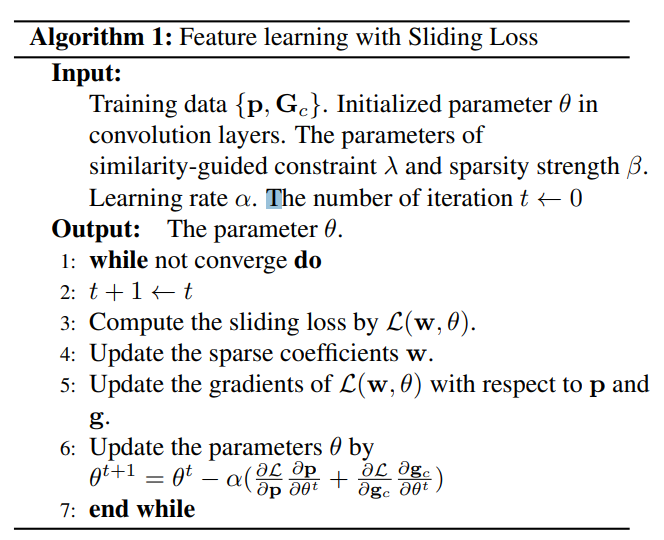
과거 논문에 의하면, 변조 인자 $a$가 hyper-parameter로 있다면, standard bi-level optimization problem(표준 이중 수준 최적화 문제.,..?)로 볼 수 있다. 즉, 내부적으로는 loss $L^a$를 최소화하는 매개변수 $w$를 학습하면서, 외부적으로는 테스트 셋인 $S_v$에 대해 rewards를 최대화 하는 weight $w^*$를 찾는다. 마지막에는 재학습 없이 사용하며, 문제를 단순화하기위해, 표준편차는 고정하고 평균은 최적화 했다. 밑의 알고리즘 1에서 확인할 수 있다.

4. Experiments
4.1 Datasets
** Training Data: CASIA-WebFace, MS-Celeb-1M Test Data: LFW, SLLFW, CALFW, CPLFW, AgeDB, CFP, RFW, MegaFace, Trillion-Pairs. Dataset Overlap Removal.**: open-set evaluation에서 training/test set 간의 겹치는 사람이 있으면 안된다. 따라서, 저자들은 CASIA-WbeFace에서 696명/ MS-Celeb-1M-v1c에서 14,718명을 제거하여 training set으로 사용했다. 표2에서 확인할 수 있다.

4.2 Experimental Settings
Data Processing.
- detect: Face-Boxes detector
- localize: 6-layer CNN
- crop size: 144x144 and RGB
- normalize: (x - 127.5) / 128
- horizontally flip (a=0.5)
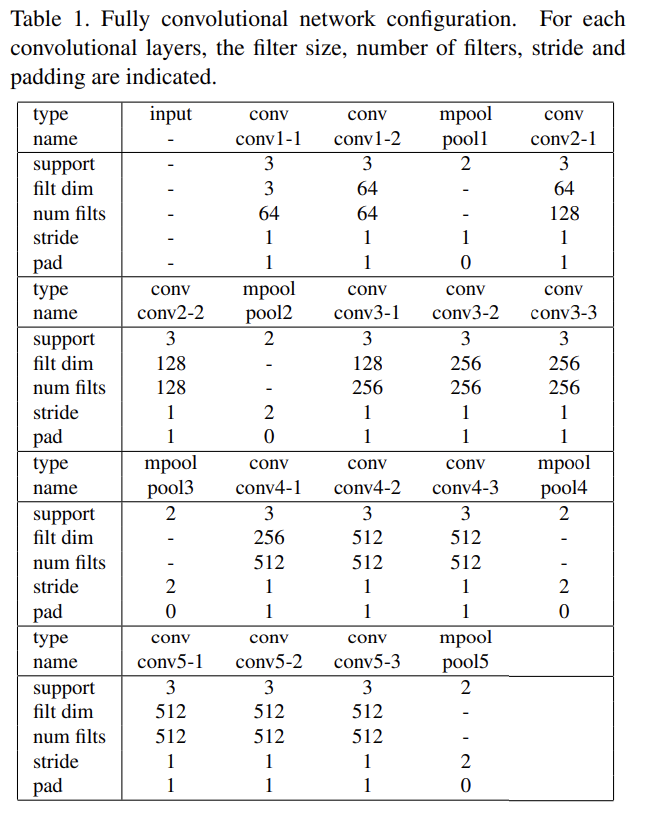
CNN Architecture. SEresNet50-IR을 사용해 512-dimension feature을 얻는다.
Training. Inner level과 outer level을 구분해서 구현 했다.
- Inner level: model parameter $w$를 최적화 한다.
- SGD optimizer
- batch size: 128
- weight decay: 0.0005
- momentum: 0.9
- learning rate: 0.1 ( [9, 18, 26] divide 10) - CASIA-WebFace-R(30) 0.1( [4, 8, 10] divide 10)- MS-Celeb-1M-v1c-R(12)
- outer level: 변조 인자 $a$를 REINFORCE로 최적화 한다. 여러 샘플들로 부터 model parameter $w^*$를 찾는 방법이다.
- Adam optimizer
- learning rate: 0.05
- 분산: 0.2
- 최적의 mean을 찾는다.
Test. 위에 제시된 dataset에서 테스트를 진행하며 original image를 사용하였다.
- Face identification: Cumulative Match CHaracteristics (CMC)
- Face verification: Receiver Operating Characteristic (ROC) 를 사용했다.
낮은 false acceptance rate (FAR)에서 true positive rate (TPR)이 강조 되는데, 실제로 false accept 보단 false rejection이 더 낮은 risk를 제공하기 때문이다.
대망의 비교 metric들은, Softmax, A-softmax, V-Softmax, AM-Softmax, Arc-Softmax 그리고 AM-LFS이다.
- AM-LFS를 제외하고는 paper에서 그대로 가져와 사용했다.
- AM-LFS는 직접 재구현하여 최고 좋은 성능을 가져와 사용했다.
- V-Softmax는 batch size와 virtual classes를 같게 함.
- A-Softmax는 $m_1=3$으로 설정함.
- Arc-Softmax와 AM-Softmax는 각각, $m_2=0.5\quad m_3=0.35$로 설정함.
- scalie parameter $s$는 32로 고정하여 사용함.
4.3 Ablation Study
Effect of reducing softmax probability.

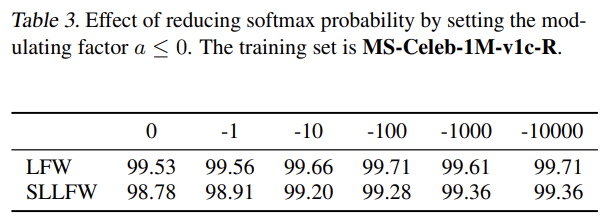
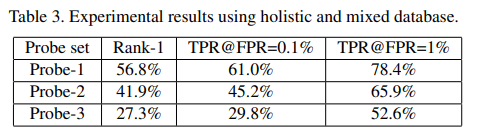
여기서는 변조 인자에 따른 softmax probability가 줄어듬에 따른 영향을 연구한다. $h(a,p)$는 단조증가함수 인데, 이것으로 인해 $p_m=h(a,p)*p$는 항상 softmax probability보다 작은 0~1사이의 값을 가지게된다. 게다가, 표3의 LFW와 SLLFW을 보면 softmax probability가 줄어들면, 성능이 증가하는 것을 확인할 수 있다. 결국, softmax probability가 줄어드는 것이 feature discrimination을 강화시켜주는 것으로 볼 수 있다.
Effect of the number of sampled models.

매개변수 $B$를 변경해가면 Search-Softmax loss를 찾았다. $B={2,4,8,16}$이며 표4에서 결과를 확인할 수 있다. B의 값에 따라 다르긴 하지만, 최적의 샘플을 찾는냐 못찾는냐의 차이인 것같다. 따라서, 저자들은 $B$를 4로 고정해서 학습을 진행하였다.
Covergence.

위의 방법들이 수렴하는 것이 이론적으로 분석하기 어렵지만, 경험적으로 수렴한다는 것을 알 수 있다. 그림 2를 보면 들쑥날쑥하지만, 수렴해 가는 것을 볼 수 있다. 명백하게 epochs이 증가할 수록 loss가 감소하며 성능이 올라가고 있다. 매개변수 $\mu$는 최적 분포를 향하고 있으므로 각 epoch에 대해 샘플링된 $a$는 더 나은 성능을 달성하기 위해 loss value를 줄이는 방향으로 간다.
4.4 Results on LFW, SLLFW, CALFW, CPLFW, AgeDB, CFP


전체적으로 좋은 성능을 보이며, Random-Search-Loss가 생각보다 좋은 성능을 보인다. 본 논문의 최적화 전략은 dynamic loss가 다른 epochs에서 사용할 수 있기 때문에 discrimination power을 더욱 높이는데 도움이 된다. 하지만, 위의 데이터셋은 포화상태여서 새로운 데이터셋이나 새로운 방법을 찾아야한다.
4.5 Results on RFW
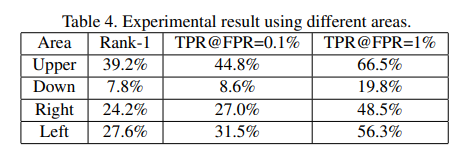
최근의 새로운 데이터 셋인 RFW에 대해 테스트를 진행했으며, racial bias를 측정하기위한 데이터셋이다. 4개의 데이터셋으로 Caucasian, Indian, Asian 그리고 African으로 이뤄져있다.


본 논문의 방법이 baseline보다 더 좋은 성능을 가져오며, 이것을 토대로 softmax probability가 줄어들면, 얼굴인식에 필요한 식별력(discrimination power)이 강화되는 것을 알 수 있다.
4.6 Results on MegaFace and Trillion-Pairs
MegaFace: identification TPR@FAR=1e-6 verification TPR@FAR=1e-6 Trillion Pairs: identification TPR@FAR=1e-3 verification TPR@FAR=1e-9
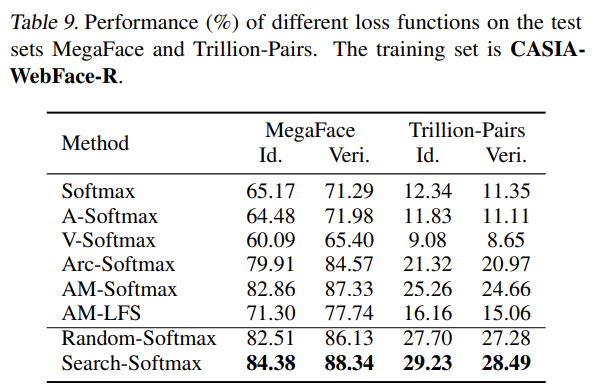
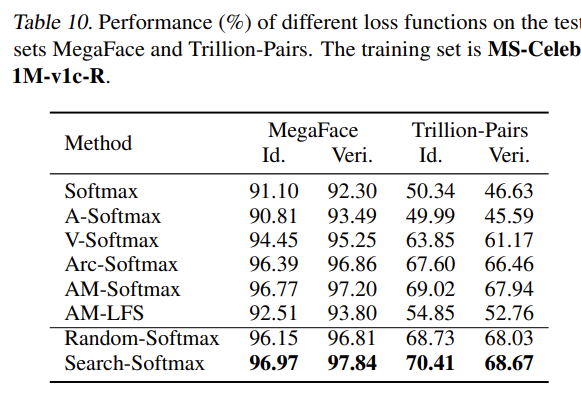
본 논문에서 제시하는 Search-Softmax가 모든 baseline보다 더 좋은 성능을 보인다.
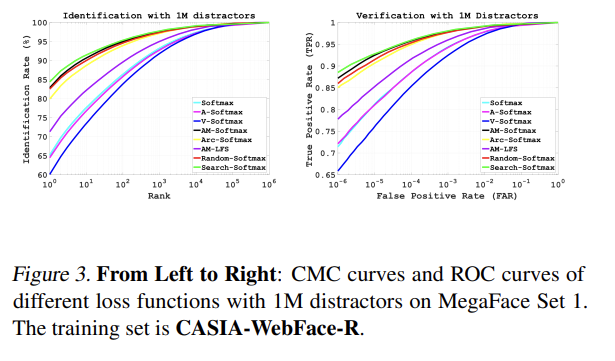
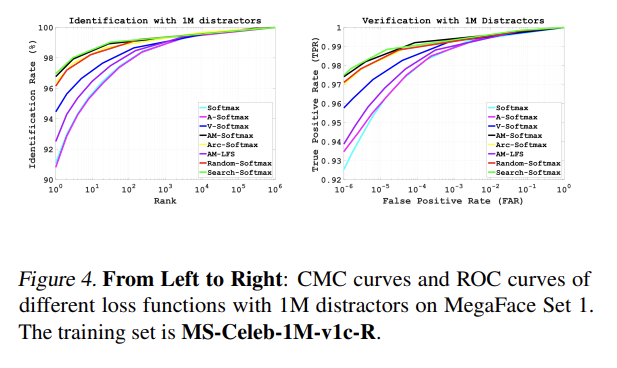
또한, MegaFace set 1에 대해 CMC curves (identification) 와 ROC curves (verification) 를 보여준다.
Trillion-Pairs Challenge와 MegaFace test set에 대해 비슷한 trends을 볼 수 있다. 즉, Search-Softmax loss가 face recognition task에 대해 큰 일반화를 보여준다고 할 수 있다.
5. Conclusion
본 논문은 얼굴인식에 필요한 식별력을 강화하는 방법이 softmax probability를 줄이는 것이라고 한다. 이러한 정보를 근거로 random-softmax / Search-Softmax를 구현했으며, softmax baseline들 보다 더 좋은 성능을 가져왔다.